Data Engineering Notes | Scala Spark 3
0. Introduction on Spark and Scala
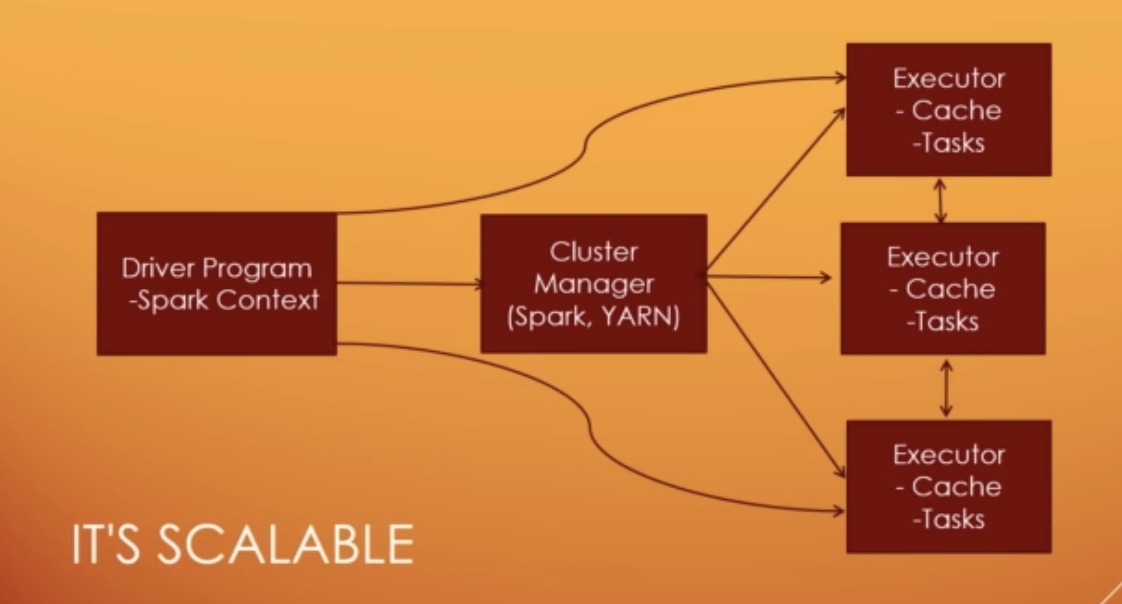
Spark
Spark: a unified analytics engine for large-scale data processing.
- fast: Run programs up to 100x faster than Hadoop Mapreduce in memory, or 10x faster on disk
- DAG(direct acyclic graph) Engine optimizes workflows
Apache Spark consists of Spark Core Engine, Spark SQL, Spark Streaming, MLlib, GraphX and Spark R.
- Spark Core: provides the in-built memory computing and referencing datasets stored in external storage systems and uses RDD data structure to speed up the data sharing in distributed processing systems like MapReduce from permanent storage like HDFS or S3 which may be slow due to the serialization and deserialization of I/O steps.
- Spark SQL: allows users to perform ETL(extract, transform and load) functions on data from a variety of sources in different formats like JSON, Parquet or Hive and then execute ad-hoc queries.
- Spark Streaming
- MLlib
- GraphX
1. Installation on MacOS
In https://spark.apache.org/docs/latest/ (updated on Sep 7, 2021)
-
Spark runs on Java 8/11, Scala 2.12, Python 3.6+ and R 3.5+.
-
Java 8 prior to version 8u92 support is deprecated as of Spark 3.0.0. For the Scala API, Spark 3.1.2 uses Scala 2.12. You will need to use a compatible Scala version (2.12.x).
-
For Java 11, -Dio.netty.tryReflectionSetAccessible=true is required additionally for Apache Arrow library. This prevents java.lang.UnsupportedOperationException: sun.misc.Unsafe or java.nio.DirectByteBuffer.(long, int) not available when Apache Arrow uses Netty internally.
-
brew cask install javashould bebrew install java --cask- https://github.com/Homebrew/discussions/discussions/902
- Error: Cask ‘java’ is unavailable: No Cask with this name exists.
- solution: https://mkyong.com/java/how-to-install-java-on-mac-osx/
- install java 8
|
|
Go to Macbook Finder, press command+shift+G and input /usr/local/Cellar
- we can see the versions of Java, Scala and Spark
- Common Issue: Setting PATH in bash
|
|
Downloads IntelliJ and install scala plugin
- Run HelloWorld.scala
|
|