Paper Notes 02 | ROCA
PaperNotes 02 | ROCA
此篇笔记是论文阅读笔记系列的第 2 篇论文,摘抄、翻译了来自 Technical University of Munich 的 Can Gümeli, Angela Dai, Matthias Niessner 三位作者在 2021 年年底发表的论文ROCA: Robust CAD Model Retrieval and Alignment from a Single Image
- 代码:https://github.com/cangumeli/ROCA
- 主页:https://cangumeli.github.io/ROCA
- 论文:https://arxiv.org/abs/2112.01988

0. Abstract:
0.1. Introduce ROCA approach
We present ROCA, a novel end-to-end approach that retrieves and aligns 3D CAD models from a shape database to a single input image.
我们提出了一种新的端到端的方法 —— ROCA,它从形状数据库中检索三维 CAD 模型并将其对准到单个输入图像。
This enables 3D perception of an observed scene from a 2D RGB observation, characterized as a lightweight, compact, clean CAD representation.
这使得能够从2D RGB 观察中对观察到的场景进行 3D 感知,其特征在于轻量、紧凑、清晰的 CAD 表示。
0.2. Core
Core to our approach is our differentiable alignment optimization based on dense 2D-3D object correspondences and Procrustes alignment.
我们的方法的核心是基于密集 2D-3D 对象对应和Procrustes 对齐的可微对齐优化。
ROCA can thus provide a robust CAD alignment while simultaneously informing CAD retrieval by leveraging the 2D-3D correspondences to learn geometrically similar CAD models.
因此,ROCA 可以提供鲁棒的 CAD 对准,同时通过利用 2D-3D 对应关系来学习几何上相似的 CAD 模型来进行 CAD 检索。
0.3. Experiments and Performance
Experiments on challenging, real-world imagery from ScanNet show that ROCA significantly improves on state of the art, from 9.5% to 17.6% in retrieval-aware CAD alignment accuracy.
对来自 ScanNet 的具有挑战性真实的世界图像进行的实验表明,ROCA 在检索感知 CAD 对准精度方面显著提高,从 9.5%提高到 17.6%.
1. Introduction
1.1. Pros and Cons of 2D Perception
Pros
2D perception systems have seen remarkable advances in object recognition from 2D images in recent years, enabling widespread adoption of systems that can perform accurate 2D object localization, classification, and segmentation from an image [23, 34, 44].
近年来,2D 感知系统在从 2D 图像识别对象方面取得了显著进步,使得能够从图像执行精确的2D 对象定位、分类和分割的系统得到广泛采用。
Such advances have spurred forward developments in many fields, from classical image understanding to robotics and autonomous driving.
这些进步推动了许多领域的发展,从经典的图像理解到机器人技术和自动驾驶。
Cons
However, unlike the human perception of 2D images, these systems tend to perform object recognition purely in 2D, whereas from a single RGB image, a human can perceive geometric shape, structure, and pose of the objects in the scene.
然而,与人类对 2D 图像的感知不同,这些(2D 感知)系统倾向于纯粹在 2D 中执行对象识别,而从单个 RGB 图像,人类可以感知场景中的对象的几何形状、结构和姿态。
In fact, such 3D understanding is crucial for many applications, enabling possible exploration and interaction with an observed environment.
事实上,这种3D 理解对于许多应用来说是至关重要的,能够实现可能的探索和与观察到的环境的交互。
1.2. 3D Approaches
At the same time, there has been notable progress in estimating 3D object geometry from visual data [10, 18, 22, 38, 46, 47].
同时,在根据视觉数据估计3D 对象几何形状方面也取得了显著进展。
Mesh R-CNN
In particular, Mesh R-CNN [21] introduced a formative approach to 3D object estimation from realworld images, bridging state-of-the-art 2D object detection with voxel-to-mesh estimation of the shape of each detected object in an image.
特别地,Mesh R-CNN[21]引入了一种 从真实世界图像进行 3D 对象估计的形成性方法,将最先进的 2D 对象检测与图像中每个检测到的对象的形状的体素到网格估计桥接起来。
Mask2CAD
In contrast to this generative approach, Mask2CAD proposed to retrieve and align CAD models from a database to produce a lightweight object reconstruction with high fidelity given by the CAD database [30, 37].
与这种生成式方法相反,Mask2CAD提出从数据库中检索和对齐 CAD 模型,以产生CAD 数据库给出的高保真度的轻量对象重建。
- [30] Mask2cad: 3d shape prediction by learning to segment and retrieve (2020)
- [37] Vid2cad: Cad model alignment using multi-view constraints from videos (2020)
CAD Model
With significant availability of synthetic CAD models [6,20,49], such CAD model reconstruction of an observed scene shows strong promise in perceiving 3D from an image, as it enables geometric estimation in a clean, compact fashion more akin to artist-crafted 3D models, and easily consumed for downstream applications
借助于合成 CAD 模型的显著可用性[ 6,20,49],场景观察得到的 CAD 模型重建在从图像感知 3D方面显示出很强的前景,因为它使得能够以更类似于艺术家制作的 3D 模型的干净、紧凑的方式进行几何估计,并且易于用于下游应用。
- [6] Shapenet: An information-rich 3d model repository. (2015)
- [20] 3d-future: 3d furniture shape with texture. (2020)
- [49] 3d shapenets: A deep representation for volumetric shapes. (2015)
1.3. Problems of current approaches and present a new approach
However, current approaches to estimate 3D object structure from an RGB image have largely focused on shape representation and generation,
然而,当前从 RGB 图像估计 3D 目标结构的方法主要集中在形状表示和生成上,
- either without any explicit pose estimation [21], 要么是没有任何显式姿态估计,
- or simply regressing the object pose directly from the 2D features of the object [17,30,31,37,39]. 要么是简单地直接从目标的 2D 特征对目标姿态进行回归处理。
Thus, we propose a new CAD retrieval and alignment approach to estimate 3D perception from an image by formulating a differentiable 9-DoF pose optimization directly coupled to the object retrieval; this enables a more robust, geometry-aware, end-to-end CAD alignment to the image.
因此,我们提出了一种新的 CAD 检索和对准方法,从而通过公式化直接耦合到目标检索的可微分 9-DoF 姿态优化来从 RGB 图像估计 3D 感知;这实现了对图像的更鲁棒的、几何形状感知的、端到端的 CAD 对准。
1.4. Details of ROCA
In this work, we propose ROCA, a new method that jointly detects object regions in a given input image while simultaneously estimating depth and dense correspondences between each 2D object region and its location in its canonical object space.
在本文中,我们提出了一种新的方法 ROCA,它在给定的输入图像中联合检测目标区域,同时估计每个 2D 目标区域与其在其规范目标空间中的位置之间的深度和稠密对应关系。
From the dense depth and correspondence estimates, we then formulate a differentiable Procrustes optimization and produce a final set of retrieved CAD models and their 9-DoF alignments.
根据密集深度和对应性估计,我们用公式表示可微分 Procrustes 优化,并产生最终的检索 CAD 模型集及其 9-DoF 的对准。
- This geometry-aware differentiable optimization for the CAD alignment of each object enables more robust and accurate CAD alignment.
- 这种用于每个对象的 CAD 对准的几何感知可微优化实现了更鲁棒和更精确的 CAD 对准。
In addition, our method learns geometry-aware embeddings for CAD retrieval. Our retrieval embedding module utilizes the canonical coordinates used in pose optimization and an auxiliary shape completion objective.
此外,我们的方法学习几何感知嵌入用于 CAD 检索. 我们的检索嵌入模块利用了姿态优化中使用的规范坐标和辅助形状补全的目标(?)。
We show learning geometry-aware embeddings improves both retrieval and alignment accuracy. Overall, our method significantly outperforms state of the art, improving by 8.1% and 9.5% in retrieval-aware alignment accuracy and alignment accuracy from a single RGB image.
我们表明,学习几何感知嵌入提高检索和对齐精度。 总体而言,我们的方法明显优于现有技术,在检索感知对准精度和基于单个 RGB 图像的对准精度方面分别提高了 8.1%和 9.5%
1.5. Summary
In summary, we propose an end-to-end architecture for CAD model alignment to an RGB image with:
- a new differentiable pose optimization enabling geometry-aware 2D-to-3D CAD alignment to an RGB image,
- improved CAD retrieval by leveraging the dense object pose correspondences and proxy CAD completion objective to inform the construction of a 【joint embedding space】 between 【detected objects and CAD models】,(通过利用所述密集对象姿态对应和代理 CAD 补全目标来生成【检测到的对象】与【CAD 模型之间】的【联合嵌入空间】的构造,从而改进 CAD 检索。)
- an interactive runtime of 53 milliseconds per image, facilitating its use in real-time applications. (快)
2. Related Work
2.1. 2D Object Recognition
We build our approach from the success of 2D recognition to extend to an end-to-end 3D object reasoning.
- In particular, to extract image features, we use a Mask-RCNN [23] recognition backbone that detects and segments objects in the image,
- from which we then estimate 3D CAD alignment and retrieval.
2.2. Monocular Depth Estimation (单目 2D 深度估计)
As we aim to predict 9-DoF object alignments, we must reason about absolute object depths. Monocular depth estimation from a single RGB image has been extensively studied to predict absolute per-pixel depths from an image.
当我们的目标是预测 9 自由度物体对准时,我们必须对绝对物体深度进行推理。 单个 RGB 图像的单目深度估计已经被广泛地研究,从而从图像预测绝对像素深度。
To extract strong geometric features, we also predict dense depth for each detected object, leveraging state-of-the-art depth estimation techniques [25,37].
为了提取强几何特征,我们还利用最先进的深度估计技术,预测每个检测到的对象的密集深度
- [25] Revisiting single image depth estimation: Toward higher resolution maps with accurate object boundaries (2019)
- [33] Deeper depth prediction with fully convolutional residual networks (2016)
2.3. Single-Image Shape Reconstruction
In recent years, many deep learning-based approaches have been developed to reconstruct 3D shapes from a 2D image. These approaches typically employ large synthetic 3D shape datasets ([6]ShapeNet), and render the synthetic objects for image input.
近年来,已经开发了许多基于深度学习的方法来用 2D 图像重构 3D 形状。 这些方法通常采用大的合成 3D 形状数据集[6],并渲染合成对象以用于图像输入。
More recent work has also focused on estimating scene layouts and inter-object relations [29, 39].
最近的工作也集中在估计场景布局和物体间的关系
- [29] 3d-relnet: Joint object and relational network for 3d prediction (2019)
- [39] Total3dunderstanding: Joint layout, object pose and mesh reconstruction for indoor scenes from a single image. (2020)
In contrast to these approaches that perform object-based reconstruction from an image, we propose to optimize for object poses by establishing dense geometric correspondences, rather than a direct regression, enabling more robust alignment optimization.
与从图像执行基于物体的重建的这些方法相比,我们提出通过建立密集的几何对应而不是直接回归来优化物体姿态,从而实现更鲁棒的对准优化。
2.4. CAD Model Retrieval and Alignment (!!!)
3D reconstruction using CAD model priors has a long history in computer vision[4, 8, 43].
利用 CAD 模型先验信息进行三维重建在计算机视觉领域有着悠久的历史。
- [4] Survey of model-based image analysis systems (1982)
- [8] Model-based recognition in robot vision (1986)
- [43] Machine perception of threedimensional solids (1963)
Recently, with the availability of large-scale 3D shape datasets, several approaches have been introduced to perform CAD model retrieval and alignment to an image based on analysis-by-synthesis reconstruction [26, 28].
- [26] Holistic 3d scene parsing and reconstruction from a single rgb image (2018)
- [28] IM2CAD(2017)
More recently, Mask2CAD [30] proposed a more lightweight approach that learns to simultaneously retrieve and 5-DoF align 3D CAD models to detected objects in an image, building on top of a state-of-the-art 2D recognition backbone [32, 35].
- [30] Mask2cad: 3d shape prediction by learning to segment and retrieve (2020)
- [32] Shapemask: Learning to segment novel objects by refining shape priors (2019)
- [35] Focal loss for dense object detection. (2017)
2.5. Learned Differentiable Pose Optimization
Most inspirational to our work is the differentiable Procrustes optimization of [3] for CAD model alignment to RGB-D scans.
对我们的工作最有启发的是[3]的微分 Procrustes 优化,用于 CAD 模型与 RGB-D 扫描的对齐。
- [3] End-to-end cad model retrieval and 9dof alignment in 3d scans. (2019)
In contrast to their work, we must reason without 3D input data, and thus formulate a notably different optimization to focus on image-based object pose estimation with per-pixel correspondences and a weighted formulation for robust alignment estimation.
与他们的工作相反,我们必须在没有 3D 输入数据的情况下进行推理,因此制定了一个明显不同的优化,以集中在具有每像素对应性的基于图像的物体姿态估计和用于鲁棒对准估计的加权公式。
3. Method
3.1. Overview
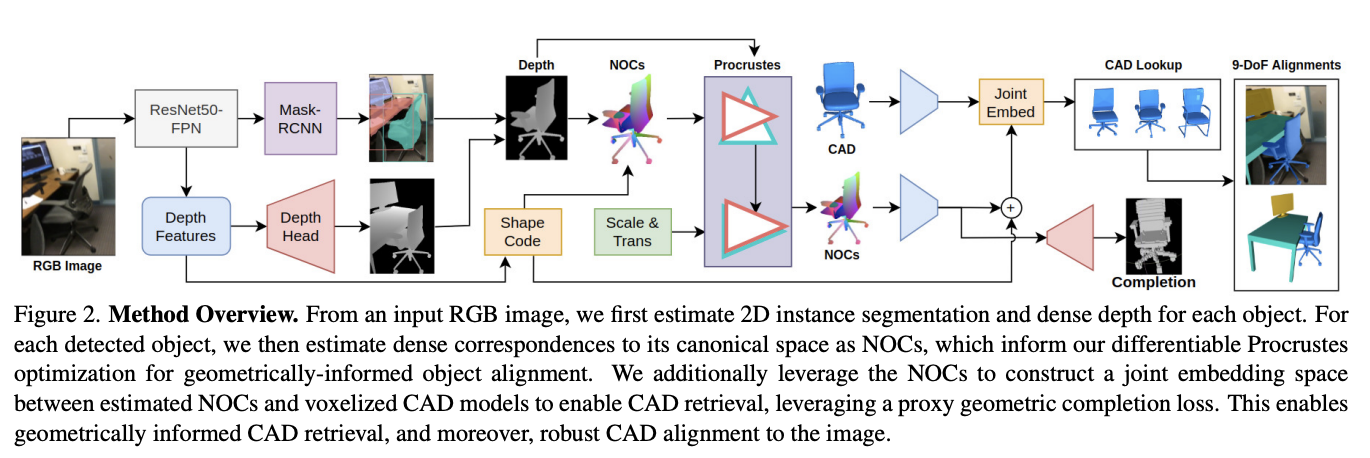
3.2. Object Recognition and Depth Estimation
For 2D object recognition, we use a Mask-RCNN [23] backbone, and for depth estimation, we use a ResNet-50-FPN [24, 34] with a Multi-scale Feature Fusion [25] module that up-projects [33] and concatenates four levels of FPN features. To up-sample depth to full image resolution, we use a pixel-shuffle layer [45]. We use a masked reverse Huber (berHu) [33] loss to optimize for depth map D.
3.3. Robust Differentiable CAD Alignment (MATH)
- Aggregating Region Features
- Scale Regression
- Initial Translation Estimation
- Normalized Object Coordinates as Correspondences
- Differentiable Robust Procrustes Optimization
3.4. Geometry-Aware CAD Retrieval
Our geometry-aware retrieval is trained end-to-end with the alignment prediction, allowing for retrieval to also inform the predicted NOC correspondences as well as the image features. At inference time, we pre-compute CAD embeddings and perform a nearest-neighbor lookup for each detected object region embedding prediction.
我们的几何感知检索是用对准预测端到端训练的,允许检索也生成预测的 NOC 对应关系以及图像特征。 在推理时,我们预先计算 CAD 嵌入,并为每个检测到的对象区域嵌入预测执行最近邻居查找。
3.5. Implementation Details
- Training
- Inference
- Implementation (PyTorch,Detectron2, PyTorch3D)
4. Results
4.1. Data and Evaluation
- Dataset: ScanNet25k, Scan2CAD
- Alignment Accuracy
- Retrieval-Aware Alignment Accuracy
4.2. Comparison to State of the Art
Figure 3 shows a qualitative comparison of CAD retrieval and alignment on ScanNet images. ROCA obtains more robust and accurate object alignments across a diverse set of image views and object types.
图 3 显示了ScanNet 图像上 CAD 检索和对齐的定性比较。 ROCA 可在各种图像视图和对象类型中获得更稳健和准确的对象对齐。

4.3. Ablations
-
Effect of end-to-end optimization on alignment (improves class alignment accuracy, from 14.9% to 19.4%.)
-
Effect of learned Procrustes weights on alignment
-
Effect of learned retrieval on alignment
-
Learned retrieval performance
-
Scaling to augmented training data
-
Limitations
5. Conclusion
5.1. Recall 0.1
We have presented ROCA, a robust end-to-end approach for single-image CAD model alignment and retrieval.
5.2. Recall 0.2.
We show that leveraging dense per-pixel depth and canonical point correspondences with our weighted differentiable Procrustes optimization leads to more robust and accurate pose predictions.
我们展示了,利用密集的每像素深度和规范点对应与我们的加权可微 Procrustes 优化可以得到更鲁棒和准确的姿态预测。
Additionally, these correspondences can be leveraged for geometry-aware end-to-end retrieval to improve both retrieval and alignment performance.
此外,这些对应性可用于几何感知的端到端检索,以改进检索和对准性能。
5.3. Recall 0.3.
For challenging ScanNet/Scan2CAD image data [2,12], our method significantly improves state-of-the-art retrieval-aware alignment accuracy from 9.5% to 17.6%. Our approach runs efficiently at test time, achieving interactive speeds of 53 milliseconds per image.
对于具有挑战性的 ScanNet/Scan2CAD 图像数据[2,12],我们的方法将最先进的检索感知对准精度从 9.5%显著提高到 17.6%。 我们的方法在测试时高效运行,实现了每张图像 53 毫秒的交互速度。
5.4. 展望未来
We hope that this can further spur developments in 3D perception towards content creation, mixed reality, and domain transfer scenarios. 我们希望这能进一步推动基于 3D 感知的内容创作、混合现实和领域转移场景发展。
