Paper Notes 01 | 3DMatch
PaperNotes 01 | 3DMatch

此篇笔记是Paper 笔记系列的第 1 篇,翻译、摘抄了 2017 年的论文3DMatch: Learning Local Geometric Descriptors from RGB-D Reconstructions
0. Abstract
0.1. Challenges and Difficulties
Matching local geometric features on real-world depth images is a challenging task due to the noisy, low resolution, and incomplete nature of 3D scan data. These difficulties limit the performance of current state-of-art methods, which are typically based on histograms over geometric properties.
由于 3D 扫描数据的噪声、低分辨率和不完整性质,在真实的世界深度图像上匹配局部几何特征是一项具有挑战性的任务。 这些困难限制了当前现有技术的方法的性能,这些方法通常基于几何属性上的直方图。
0.2. Paper Intro
In this paper, we present 3DMatch, a data-driven model that learns a local volumetric patch descriptor for establishing correspondences between partial 3D data. To amass training data for our model, we propose a self-supervised feature learning method that leverages the millions of correspondence labels found in existing RGB-D reconstructions.
本文提出了一种基于数据驱动的 3DMatch 模型,该模型通过学习局部体积块描述符来建立局部三维数据之间的对应关系。 为了积累模型的训练数据,我们提出了一种自监督特征学习方法,该方法利用了现有 RGB-D 重建中发现的数百万个对应标签。
0.3. Experiments and Results
Experiments show that our descriptor is not only able to match local geometry in new scenes for reconstruction, but also generalize to different tasks and spatial scales (e.g. instance-level object model alignment for the Amazon Picking Challenge, and mesh surface correspondence).
实验表明,该描述符不仅能够匹配新场景中的局部几何结构,而且能够推广到不同的任务和空间尺度(例如 Amazon Picking Challenge 的实例级对象模型对齐,以及网格表面对应)。
Results show that 3DMatch consistently outperforms other state-of-the-art approaches by a significant margin.
结果表明,3DMatch 始终以显著优势优于其他最先进的方法。
Code, data, benchmarks, and pre-trained models are available online at http://3dmatch.cs.princeton.edu.
1. Introduction
1.1. History and Applications
Matching 3D geometry has a long history starting in the early days of computer graphics and vision.
匹配 3D 几何图形有着悠久的历史,它始于计算机图形学和视觉的早期。
With the rise of commodity range sensing technologies, this research has become paramount to many applications including object pose estimation, object retrieval, 3D reconstruction, and camera localization.
随着商用距离传感技术的兴起,该研究对于包括物体姿态估计、物体检索、3D 重建和摄像机定位在内的许多应用变得至关重要。
1.2. Challenges ( ==> 0.1)
However, matching local geometric features in low resolution, noisy, and partial 3D data is still a challenging task as shown in Fig. 1.

- Figure 1. In this work, we present a data-driven local descriptor 3DMatch that establishes correspondences (green) to match geometric features in noisy and partial 3D scanning data.
- This figure illustrates an example of bringing two RGB-D scans into alignment using 3DMatch on depth information only.
- Color images are for visualization only.
While there is a wide range of low-level hand-crafted geometric feature descriptors that can be used for this task, they are mostly based on signatures derived from histograms over static geometric properties[19,22,28].
虽然有大量的低级手工几何特征描述符可用于此任务,但这些描述符大多基于从静态几何属性的直方图中派生的
They work well for 3D models with complete surfaces, but are often unstable or inconsistent in real-world partial surfaces from 3D scanning data and difficult to adapt to new datasets.
它们对于具有完整表面的 3D 模型工作良好,但是在来自 3D 扫描数据的真实的世界部分表面中通常不稳定或不一致,并且难以适应新的数据集。
As a result, state-of-the-art 3D reconstruction methods using these descriptors for matching geometry require significant algorithmic effort to handle outliers and establish global correspondences [5]
1.3. Ideas of 3DMatch (==> 0.2)
In response to these difficulties, and inspired by the recent success of neural networks, we formulate a data-driven method to learn a local geometric descriptor for establishing correspondences between partial 3D data.
针对这些困难,并受到神经网络最近成功的启发,我们制定了一种数据驱动的方法来学习局部几何描述符,以建立局部 3D 数据之间的对应关系。
The idea is that by learning from example, data-driven models can sufficiently address the difficulties of establishing correspondences between partial surfaces in 3D scanning data.
其思想是,通过从示例中学习,数据驱动的模型可以充分解决在 3D 扫描数据中建立部分表面之间的对应关系的困难。
To this end, we present a 3D convolutional neural network (ConvNet), called 3DMatch, that takes in the local volumetric region (or 3D patch) around an arbitrary interest point on a 3D surface and computes a feature descriptor for that point, where a smaller distance between two descriptors indicates a higher likelihood of correspondence.
为此,我们提出了一种称为 3DMatch 的 3D 卷积神经网络(ConvNet),它采用 3D 表面上任意感兴趣点周围的局部体积区域(或 3D 块),并计算该点的特征描述符,其中两个描述符之间的距离越小,对应的可能性越高。
1.4. Challenges for 3D Data collection
However, optimizing a 3D ConvNet-based descriptor for this task requires massive amounts of training data (i.e.,ground truth matches between local 3D patches).
然而,为该任务优化基于 3D ConvNet 的描述符需要大量的训练数据(即,局部 3D 面片之间的基准匹配)。
Obtaining this training data with manual annotations is a challenging endeavor. Unlike 2D image labels, which can be effectively crowd-sourced or parsed from the web, acquiring ground truth correspondences by manually clicking keypoint pairs on 3D partial data is not only time consuming but also prone to errors.
通过手动标注获取训练数据是一项具有挑战性的工作。与可以有效地众包或从网络解析的 2D 图像标签不同,通过手动点击 3D 部分数据上的关键点对来获取匹配关系不仅耗时,而且容易出错。
1.5. Solution to 1.4
Our key idea is to amass training data by leveraging correspondence labels found in existing RGB-D scene reconstructions.
我们的关键思想是通过利用现有 RGB-D 场景重建中发现的对应标签来积累训练数据。
Due to the importance of 3D reconstructions, there has been much research on designing algorithms and systems that can build high-fidelity reconstructions from RGB-D data[25,26,8].
由于 3D 重建的重要性,已经有很多关于设计能够从 RGB-D 数据构建高保真重建的算法和系统的研究。
Although these reconstructions have been used for high-level reasoning about the environment it is often overlooked that they can also serve as a massive source of labeled correspondences between surfaces points of aligned frames.
尽管这些重建已经用于关于环境的高级推理,但是经常被忽视的是,它们也可以用作对齐的框架的表面点之间的标记对应的大量资源。
By training on correspondences from multiple existing RGB-D reconstruction datasets, each with its own properties of sensor noise, occlusion patterns, variance of geometric structures, and variety of camera viewpoints, we can optimize 3DMatch to generalize and robustly match local geometry in real-world partial 3D data.
通过对来自多个现有 RGB-D 重建数据集的对应性进行训练,每个数据集都具有其自身的传感器噪声、遮挡模式、几何结构的变化和相机视点的多样性的属性,我们可以优化 3DMatch,从而推广和稳健匹配真实的世界部分 3D 数据中的局部几何结构。
1.6. Experiments and Results( == 0.3)
In this paper, we train 3DMatch over 8 million correspondences from a collection of 62 RGB-D scene reconstructions [37, 31, 40, 21, 16] and demonstrate its ability to match 3D data in several applications.
在本文中,我们从 62 个 RGB-D 场景重建的集合中训练了超过 800 万个对应的 3DMatch,并证明了其在几个应用中匹配 3D 数据的能力。
Results show that 3DMatch is considerably better than state-ofthe-art methods at matching keypoints, and outperforms other algorithms for geometric registration when combined with standard RANSAC.
实验结果表明,3DMatch 算法在关键点匹配方面明显优于现有算法,与标准 RANSAC 算法相结合的几何配准性能优于其他算法。
Furthermore, we demonstrate that 3DMatch can also generalize to different tasks and spatial resolutions. For example, we utilize 3DMatch to obtain instance-level model alignments for 6D object pose estimation as well as to find surface correspondences in 3D meshes.
此外,我们还证明了3DMatch 也可以推广到不同的任务和空间分辨率。 例如,我们利用 3DMatch 来获得实例级模型对准,以用于6D 对象姿态估计以及在3D 网格中找到表面对应。
To facilitate further research in the area of 3D keypoint matching and geometric registration, we provide a correspondence matching benchmark as well as a surface registration benchmark similar to [5], but with real-world scan data.
为了促进3D 关键点匹配和几何配准领域的进一步研究,我们提供了类似于[5]的对应匹配基准以及表面配准基准,但使用的是真实的世界的扫描数据。
2. Related Work
2.1. Hand-crafted 3D Local Descriptors:
- Spin Images[19]
- Geometry Histograms[12]
- Signatures of Histograms[35]
- Feature Histograms[29]
Problem: they still struggle to handle noisy, low-resolution, and incomplete real-world data from commodity range sensors.
Solution: The goal of our work is to provide a new local 3D descriptor that directly learns from data to provide more robust and accurate geometric feature matching results in a variety of settings.
2.2. Learned 2D Local Descriptors
Various works [33, 32, 42, 17, 43, 17] (that are trained on data generated from multi-view stereo datasets[4])learn non-linear mappings from local image patches to feature descriptors.
Problem: multi-view stereo is difficult to scale up in practice and is prone to error from missing correspondences on textureless or non-Lambertian surfaces, so it is not suitable for learning a 3D surface descriptor.
2.3. Learned 3D Global Descriptors
- 3D ShapeNets[39] introduced 3D deep learning for modeling 3D shapes
- several recent works [23, 11, 34] also compute deep features from 3D data for the task of object retrieval and classification.
- Compare: their focus is centered on extracting features from complete 3D object models at a global level
In contrast, our descriptor focuses on learning geometric features for real-world RGB-D scanning data at a local level, to provide more robustness when dealing with partial data suffering from various occlusion patterns and viewpoint differences
2.4. Learned 3D Local Descriptors
[15] operates only on synthetic and complete 3D models, while using 2D ConvNets over input patches of concatenated feature vectors that do not have any kind of spatial correlation.
In contrast, our work not only tackles the harder problem of matching real-world partial 3D data, but also properly leverages 3D ConvNets on volumetric data in a spatially coherent way.
2.5. Self-Supervised Deep Learning
Our method of extracting training data and correspondence labels from existing RGB-D reconstructions online is fully automatic, and does not require any manual labor or human supervision.
3. Learning From Reconstructions
3.1. Generating Training Correspondences (TODO)
4. Learning a Local Geometric Descriptor
We use a 3D ConvNet to learn the mapping from a volumetric 3D patch to an 512-dimensional feature representation that serves as the descriptor for that local region.
4.1. 3D Data Representation (TODO)
4.2. Network Architecture
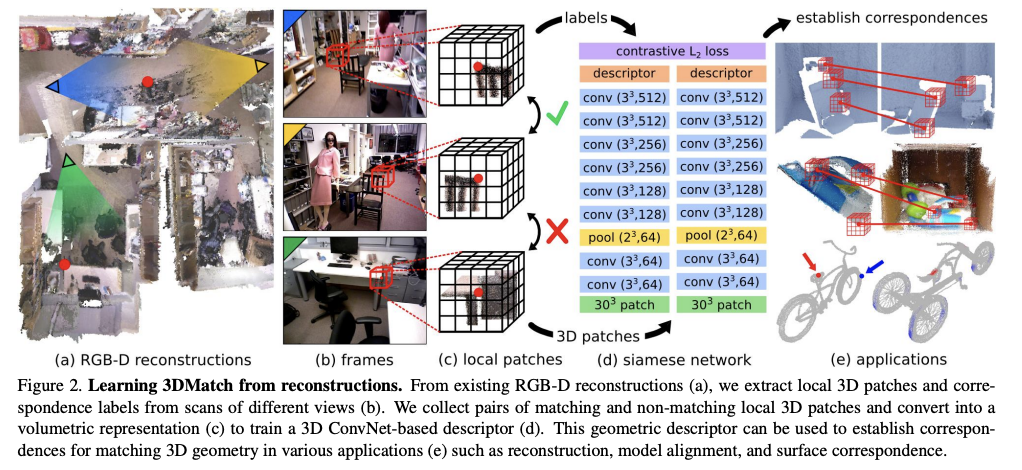
4.3. Network Training
5. Evaluation
5.1. Keypoint Matching
5.2. Geometric Registration
5.2.2. Integrate 3D Match in Reconstruction Pipeline
- Traditionally, sparse RGB features, such as SIFT or SURF, are used to tablish feature matches between frames
- With 3DMatch, we are able to establish keypoint matches from geometric information and add to the bundle adjustment step.
- With this simple pipeline we are able to generate globally-consistent alignments in challenging scenes using only geometric information

- In Fig. 6, we show several reconstruction results where combining correspondences from both SIFT (color) and 3DMatch (geometry) improves alignment quality as a whole.
5.3.1. 6D Object Pose Estimation by model alignment
The task is to register pre-scanned object models to RGB-D scanning data for the Shelf & Tote benchmark in the Amazon Picking Challenge (APC) setting

3DMatch + RANSAC works well for many cases; however, it may fail when there is insufficient depth information due to occlusion or clutter (bottom).

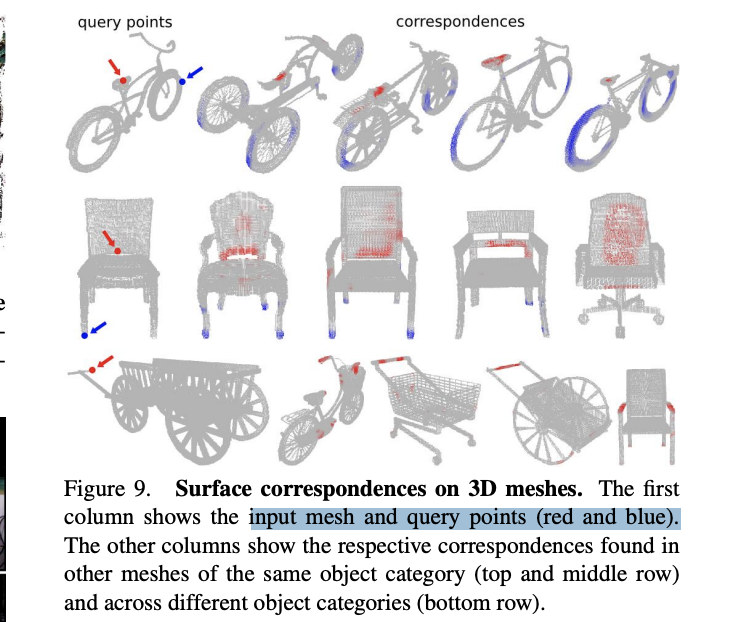
5.3.2. Surface Correspondence on 3D Meshes
Interestingly 3DMatch is also able to find geometric correspondences across different object categories.
- For example in the third row of Fig. 9, 3DMatch is able to match the handles in very different meshes.
6. Conclusion
In this work, we presented 3DMatch, a 3D ConvNet-based local geometric descriptor that can be used to match partial 3D data for a variety of applications.
在本文中,我们提出了 3DMatch,一种基于 3D ConvNet 的局部几何描述符,可用于匹配不完整的 3D 数据,以满足各种应用。
We demonstrated that by leveraging the vast amounts of correspondences automatically obtained from RGB-D reconstructions, we can train a powerful descriptor that outperforms existing geometric descriptors by a significant margin.
我们证明,通过利用从 RGB-D 重建中自动获得的大量对应关系,我们可以训练一个强大的描述符,该描述符以显著的优势优于现有的几何描述符。
We make all code and pre-trained models available for easy use and integration. To encourage further research, we also provide a correspondence matching benchmark and a surface registration benchmark, both with real-world 3D data.
我们提供所有代码和预先训练的模型,以方便使用和集成。 为了鼓励进一步的研究,我们还提供了对应匹配基准和表面配准基准,两者都使用真实的世界的 3D 数据。