Time Series Note | Financial Time Series Analysis
1. Introduction to Time Series in Python
Time Series is a sequence of information which attaches a time period to each value
- A common topic in Time Series Analysis is determining the stability of financial markets and the efficiency protfolios (效率投资组合)
Properties
All time-periods must be equal and clearly defined, which would result in a constant frequency
- Frequency: how often values of the data set are recorded
- if the intervals are not identical => dealing with missing data
Time-Dependency(时效性): the values for every period are affected by outside factors and by the values of past periods
- in chronological order
- from a machine learning perspective, this is inconvenient for train/test data split
- we need pick a cut-off point and let the period before the cut-off point be the training set and the period after the cutoff point be the testing set
Python Implementation
Step1: Import the library and read the file
- Create a copy of original data in case we erase certain values and read the csv file again
df.head()shows the information of the top five observations for the data set
|
|
Output:
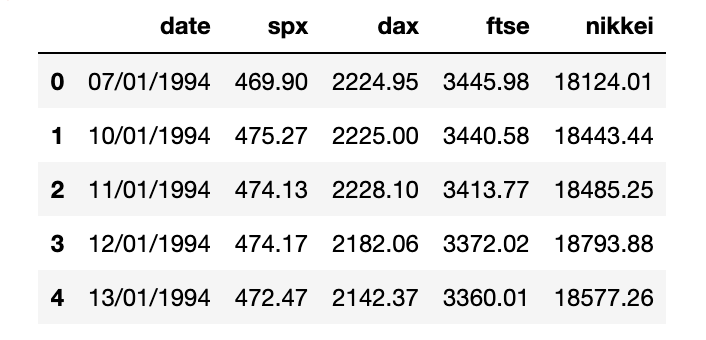
date: represents the day when the values of the other columns (closing prices of four market indexes) were recorded- Each market index is a portfolio of the most traded companies on the respective stock exchange markets:
spx: S&P 500 measures the stability of the US stock exchangesdax: DAX 30 measures the stability of the German stock exchangesftse: FTSE 100 measures the stability of the London Stock exchangesnikkei: NIKKEI 225 measures the stability of the Japanese stock exchanges
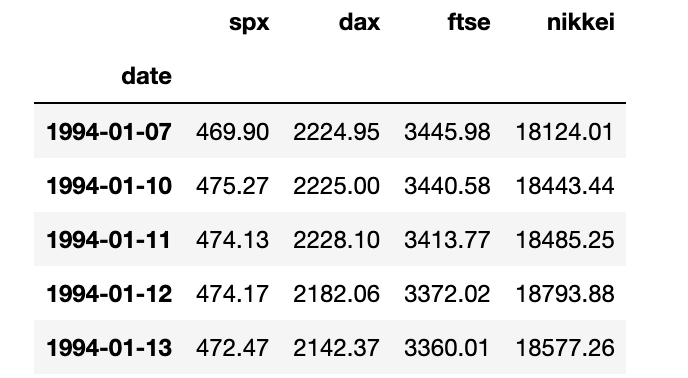
Step2: Transform “dd/mm/yyyy” format to “yyyy-mm-dd” datetime format
- set
dateas index:inplace = Truelets date replace the integer index- Once “date” becomes an index, we no longer save/modify its values as a seperate attribute in the data frame
- set frequency:
- arguments: ‘h’ - hourly, ‘w’ - weekly, ’d' - daily, ’m' - monthly
- not interested in any weekends or holidays => missing values NaN
- ‘b’ - business days
|
|
Output:
Step3: Handling Missing Values
- For each attribute,
df_comp.isna().sum()will show the number of instances without available information for each column - Setting the frequency to “business days” must have generated 8 dates, for which we have no data available
fillna()method:- front filling: assigns the value of the previous period
- back filling: assigns the value for the next period
- assigning the same average to all the missing values (bad approach)
|
|
Step4: Adding and Removing Columns
- just keep the index
timeandspxasmarket_value
|
|
Step5: Splitting the Time-Series data
- since time series data relies on keeping the chronological order of the values
- cannot “shuffle” the data before splitting
Training Set: From the beginning up to some cut off pointTesting Set: From the cut off point until the end80-20split is resonable- training set too large: performs poorly with new data
- training set too small: cannot create an accurate model
iloccomes fromindex locationlencomes fromlengthintensures that thetrain_sizewill be integer
|
|
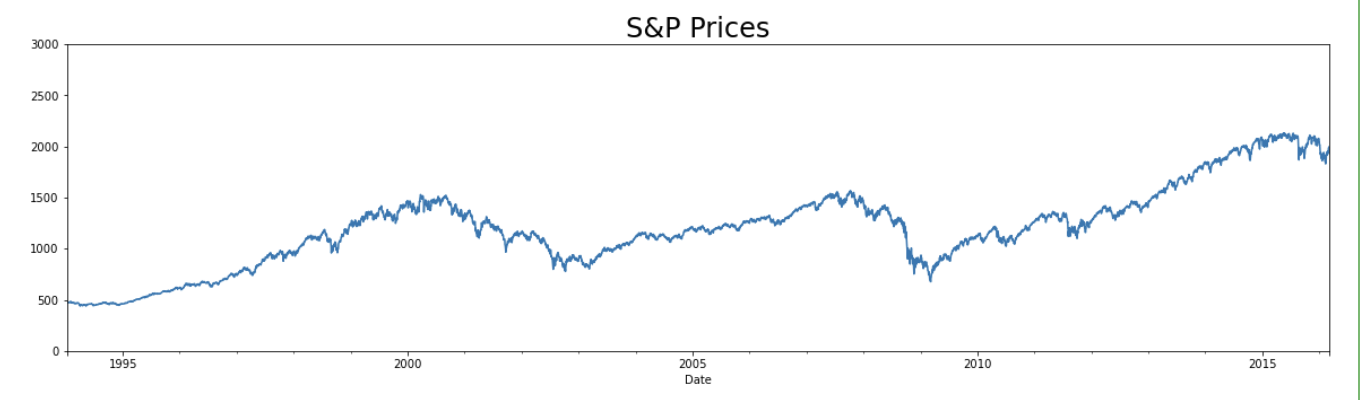
Step6: Data Visualization
|
|
Output:
The QQ Plot is a tool used to determine whether a data set is distributed a certain way (normal)
|
|
Output:
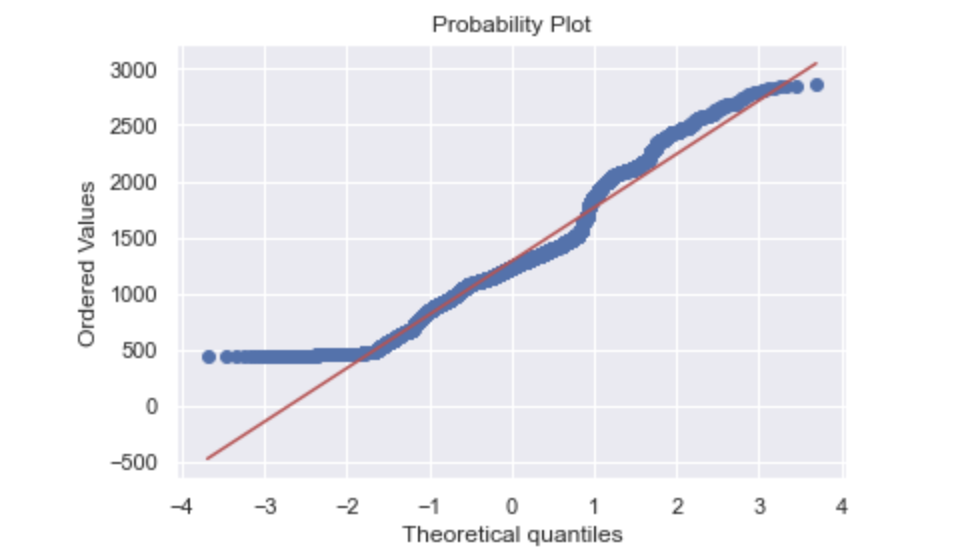
Explanation:
- QQ plot takes all the values and arranges them in accending order.
- y represents how many standard deviations away from the mean
- The red diagonal line represents what the data points should follow if they are Normal Distributed
- In this case, since more values are arond 500, the data is not normally distributed
- and we cannot use the elegant statistics of Normal Distributions to make successful forecasts
Extra Step: Scrape the real-time data off of Yahoo Finance
|
|
3. White Noise
Definition: A sequence of random data, where every value has a time-period associated with it
- it behaves sporadically, not predictable
Conditions:
- constant mean $\mu$
- constant variance $\sigma^2$
- no autocorrelation in any period: NO clear relationship between past and present values
- autocorrelation measures how correlated a series is with past versions of itself
- $\rho = corr(x_t,x_{t-1})$
Generate White Noise data and plot its values
- compare with the graph of the
S&Pclosing prices
|
|
Output:
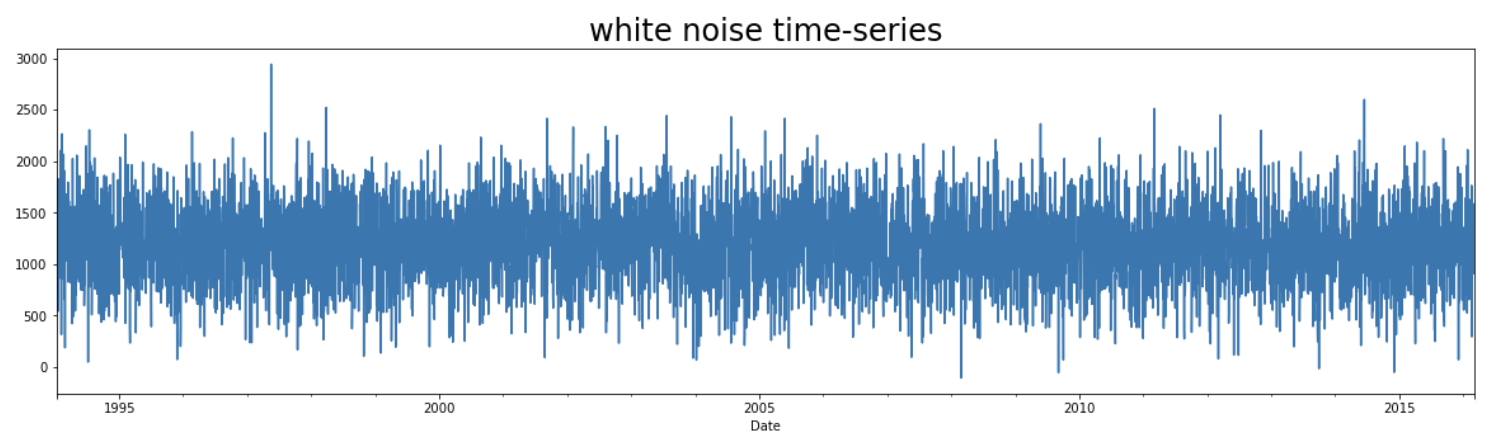
4. Random Walk
Definition: A special type of time-series, where values tend to persist over time and the differences between periods are simply white noise
- $P_t = P_{t-1} + \epsilon_t$, where the residual $\epsilon_t \sim WN(\mu,\sigma^2)$
The random walk data is much more similar to S&P prices than to white noise values
- both have small variations between consecutive time periods
- both have cyclical increases and decreases in short periods of time
|
|
Output:
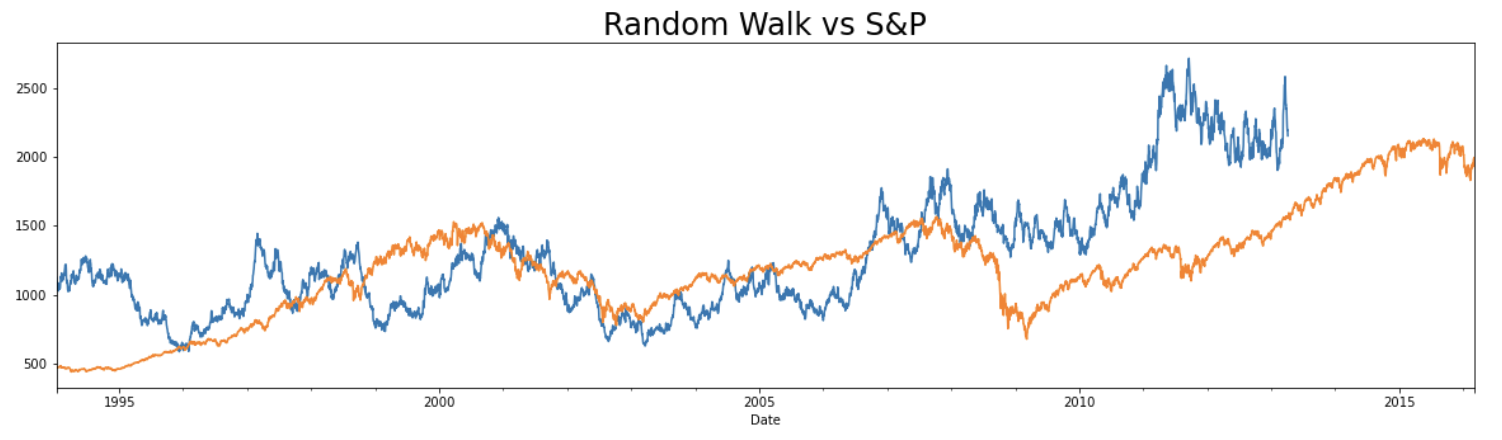
Market Efficiency: measures the level of difficulty in forecasting correct future values
- in general, if a time series resembles a random walk, the prices can’t be predicted with great accuracy
- conversely, if future prices can be predicted with great accuracy, then there are arbitrage opportunities
- we can speak of arbitrage when investors manage to buy and sell commodities and make a safe profit while the price adjusts
- if such opportunities exist within a market, investors are bound to take advantage, which would eventually lead to a price that matches the expected one, as a result, prices adjust accordingly
5. Stationarity
Strict Stationarity
Rarely observed in nature
- $(x_t,x_{t+k}) \sim Dist(\mu, \sigma^2)$
- $(x_{t+a},x_{t+a+k}) \sim Dist(\mu, \sigma^2)$
Weak-form/Covariance Stationarity
Assumptions:
- Constant $\mu$
- Constant $\sigma^2$
- $Cov(x_n,x_{n+k}) = Cov(x_m, x_{m+k})$
- consistent covariance between periods at an identical distance
Dickey-Fuller Test: to check whether a data set comes from a stationary process
- Null Hypothesis: assumes non-stationarity
- autocorrelation coefficient $\varphi < 1$
- Alternative Hypothesis: $\varphi = 1$
- reject the Null if
test statistic<critical valuein the D-F Table- stationarity
|
|
6. Seasonality
Trends will appear on a cyclical basis.
Ways to test for seasonality:
- Decompose the sequence by splitting the time series into 3 effects:
- Trend: represents the pattern consistent throughout the data and explains most of the variability of the data
- Seasonal: expresses all cyclical effects due to seasonality
- Residual: the difference between true values and predictions for any period
Naive Decomposition: Decomposition function uses the previous period values as a trend-setter.
- Additive: observed = trend + seasonal + residual
- Multiplicative: observed = trend x seasonal x residual
|
|
Both Output:
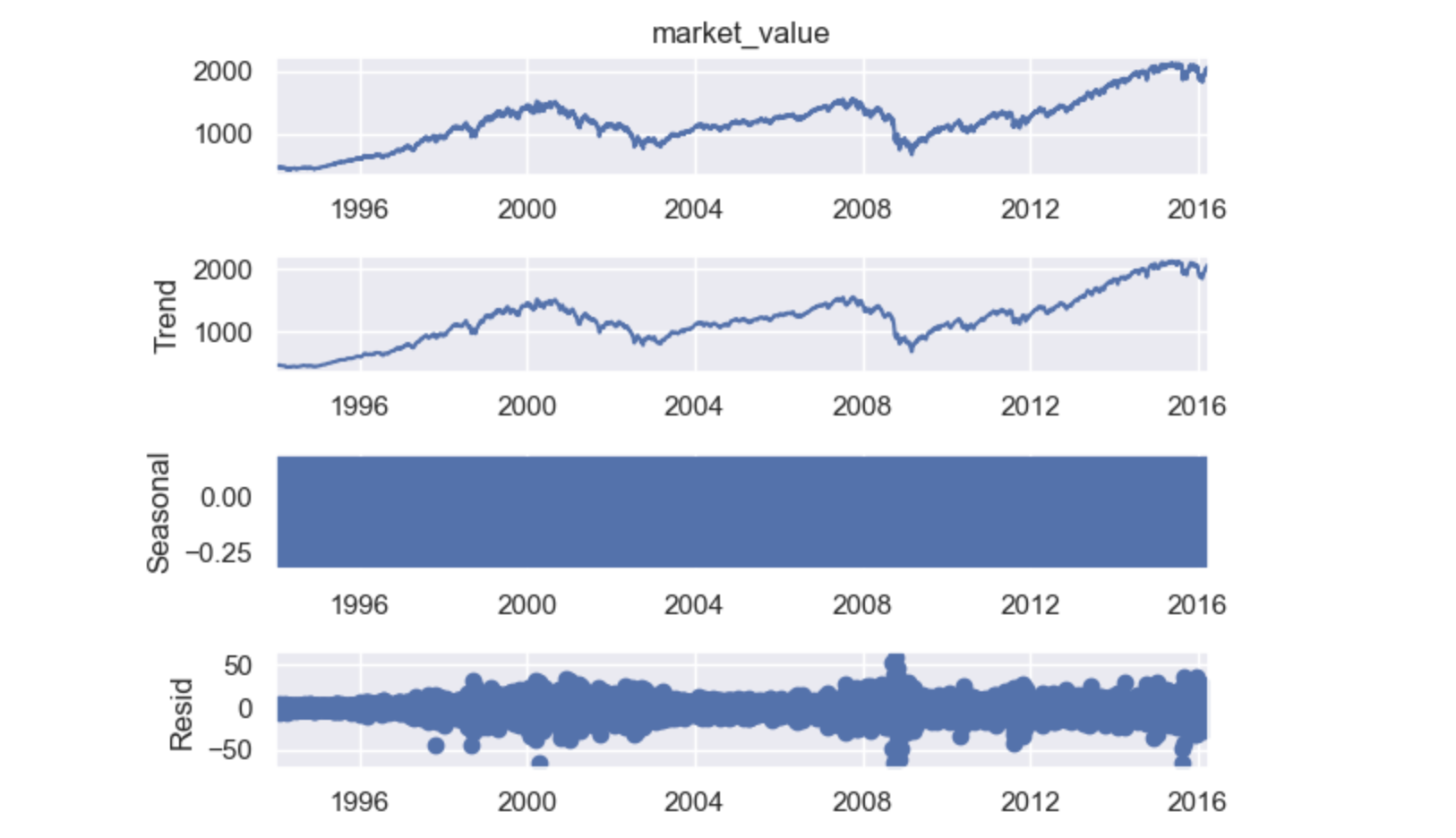
The residuals vary greatly around 2000 and 2008,
- this can be explained by the instability caused by the
.comandhousing pricesbubbles respectively
Seasonal looks like a rectangle:
- values are constantly oscillating back and forth and the figure size is too small
- no concrete cyclical pattern
- => no seasonality in the S&P data
7. The Autocorrelation Function (ACF)
Correlation measures the similarity in the change of values of two series
- $\rho(x,y)$ only have a single variable
Autocorrelation is the correlation between a sequence and itself
- measures the level of resemblance between a sequence from several periods ago and the actual data
Laggedis a delayed series of the original one- how much of yesterday’s values resemble today’s values, or similarities from year to year
ACF for S&P market value
|
|
Output:
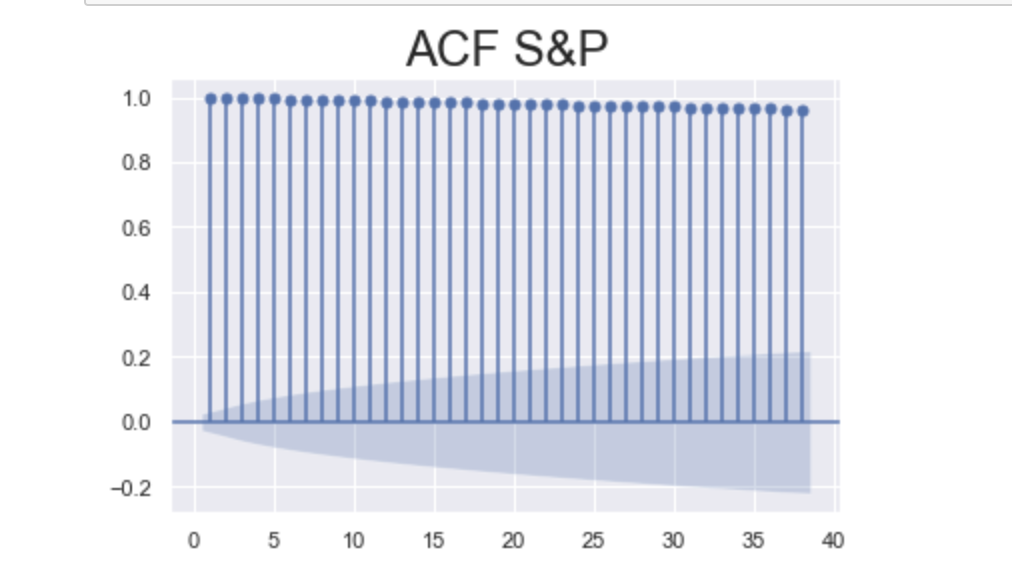
Explanation:
- x-axis: represents lags,
- y-axis: indicates the possible values for the autocorrelation coefficient
- correlation can only take values between -1 and 1,
- lines across the plot represent the autocorrelation between the time series and a lagged copy of itself
- the first line represents the autocorrelation coefficient for one time period ago
- the
blue areaaround the x-axis representssignificance, the values situated outside are significantly different from zero which suggests the existence of autocorrelation for that specific lag - the greater the distance in time, the more UNLIKELY it is that this autocorrelation persists
- e.g. today’s prices are usually closer to yesterday’s prices than the prices a month ago
- therefore, we need to make sure the autocorrelation coefficient in higher lags is sufficiently greater to be significantly different from zero
- notice how all the lines are positive and higher than the blue region, this suggests the coefficients are significant, which is an indicator of time dependence in the data
- also, we can see that autocorrelation barely diminishes as the lags increase, this suggests that prices even a month back (40 days ago) can still serve as decent estimators for tomorrow
ACF for White Noise
|
|
Output:
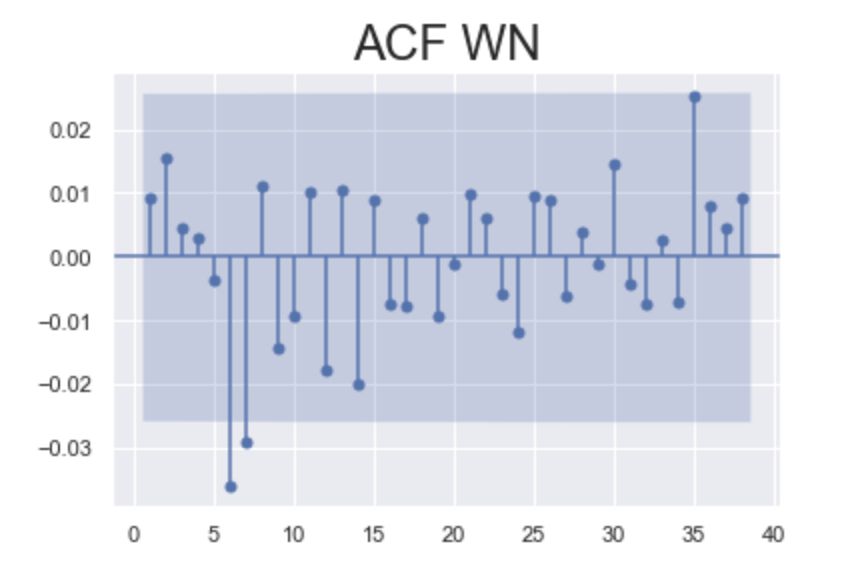
Explanation:
- Since white noise series is generated randomly
- there are patterns of positive and negative autocorrelation
- All the lines fall within the
blue area, thus the coefficients areNOT significantacross the entire plot- No autocorrelation for any lag
8. The Partial Autocorrelation Function (PACF)
ACF: Prices 3 days ago,
- affecting values of 1 and 2 days ago, which in turn affect present prices indirectly
- affecting present prices directly
PACF cancels out ALL additional channels a previous period value affects the present one
- $X_{t-2}$ => $X_t$
- Cancel Out: $X_{t-2}$ => $X_{t-1}$ => $X_t$
|
|
Output:
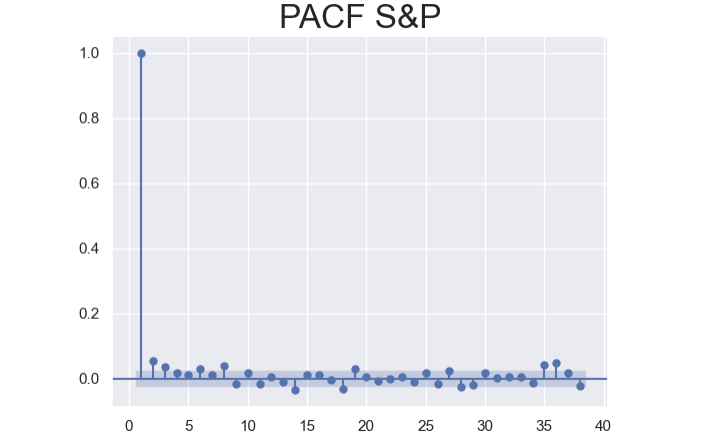
Explanation:
- PACF and ACF values for the first lag should be indentical
- Not significantly different from 0 except the first several lags
- a tremendous contrast to the ACF plot (all 40 lags are significant)
- Being positive or negative is somewhat random without any lasting effects
- negative values may be caused from Weekends.
9. The Autoregressive (AR) Model
Autoregressive Model is a linear model, where current period values are a sum of past outcomes multiplied by a numeric factor
- “autoregressive” because the model uses a lagged version of itself (auto) to conduct the regression
- use PACF to select the correct AR model because it shows the individual direct effect each past value has on the current one
- AR(2): $x_{t} = C + \phi_1 x_{t-1} + \phi_2 x_{t-2} + \epsilon_t$
- $ -1 < \phi < 1 $
- $\epsilon_t$: Residuals represent the
unpredictabledifferences between our prediction for period “t” and the correct value - More lags -> More complicated model -> more coefficients -> some of them are more likely not significant
Fitting an AR(1) Model for Index Prices
Fitting the model: Find the most appropriate coefficients
|
|
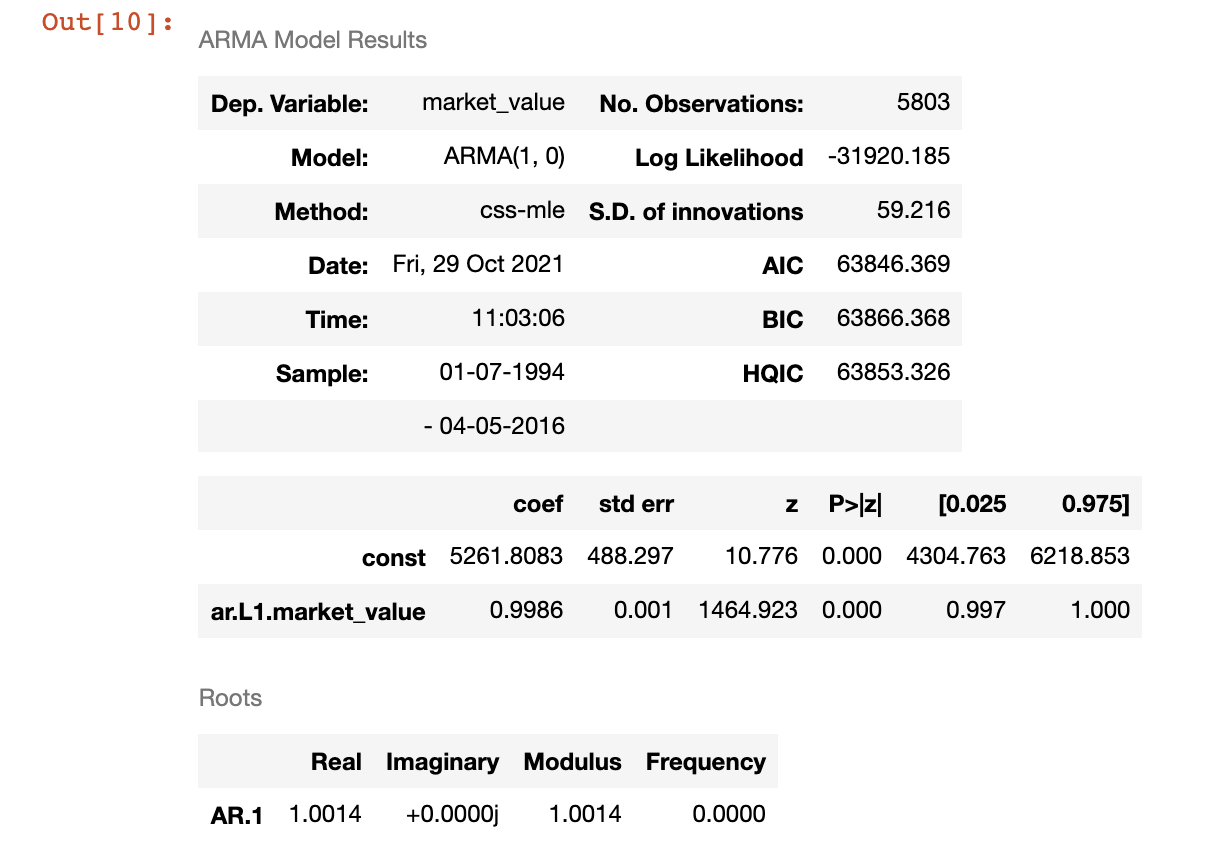
Explanation:
For AR(1) Model: $x_{t} = C + \phi_1 x_{t-1} + \epsilon_t$
- C = 5261.8083
- $\phi_1$ = 0.9986
std errorrepresents how far away, on average, the model’s predictions are from the true values- p = 0 means that the coefficients are significantly different from zero
Fitting Higher-Lag AR Models and LLR
Fit AR(2) Model: $x_t = C + \phi_1 x_{t-1} + \phi_2 x_{t-2} + \epsilon_t$
|
|
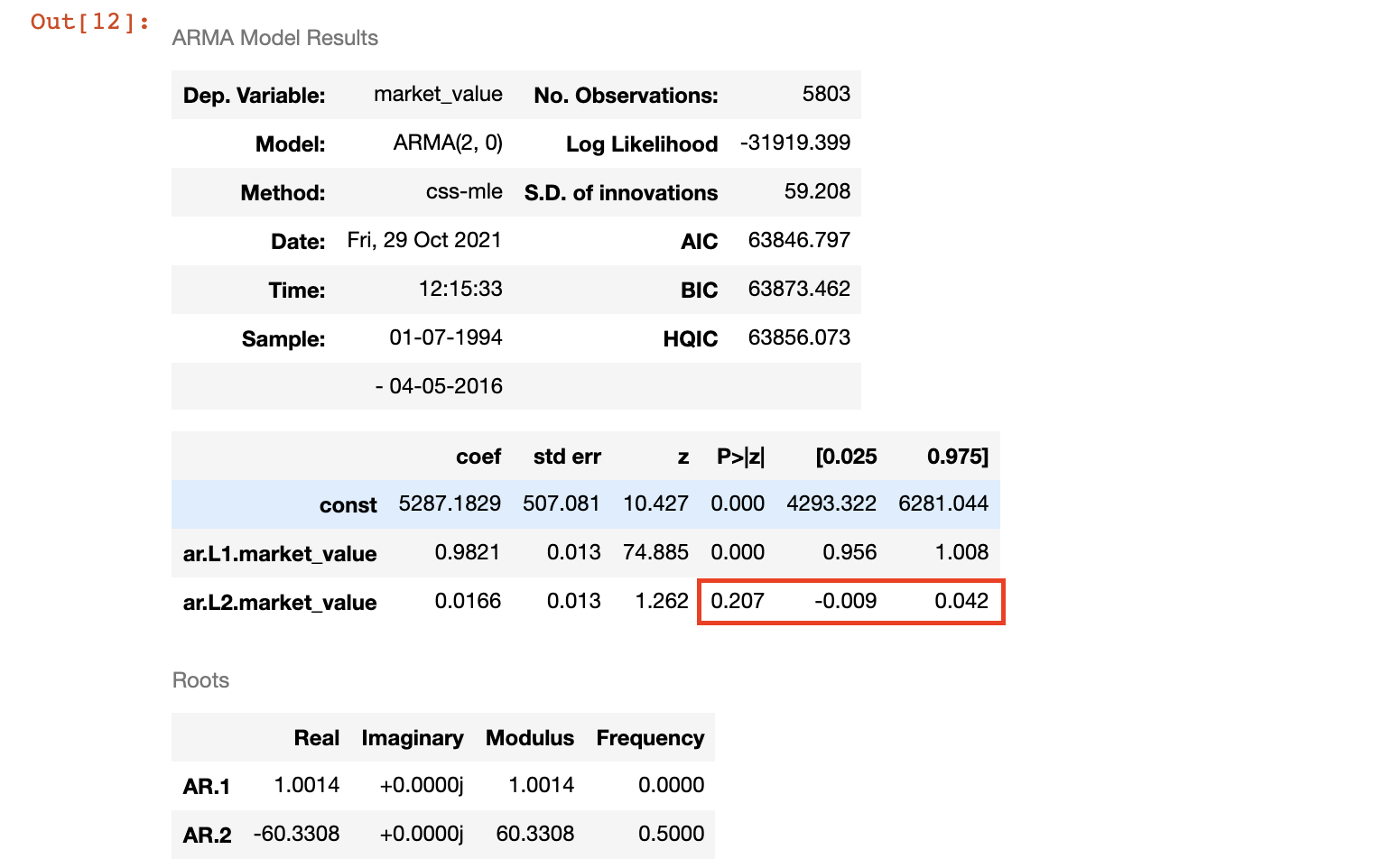
- p = 0.226 > 0.05, reject the H0, $\phi_2$ is NOT significantly different from 0
- the prices two days ago do not significantly affect today’s prices
Fit AR(3) Model:
ar.L2.market_valuefrom 0.0166 to -0.0292- its p-value 0.112 is still greater than 0.05
Log Likelihoodfrom -31919.399 to -31913.087- higher Log-Likelihood => Lower Information criterion (AIC, BIC, HQIC)
Use Log-Likelihood Ratio (LLR) Test to determine whether a more complex model makes better predictions
|
|
Fitting more complicated models and checking if it gives us Distinguishably Greater Log-Likelihood, then stop before the model that satisfies:
- Non-significant p-value for the LLR Test (> 0.05)
- Non-significant p-value for the highest lag coefficient
|
|
Output:
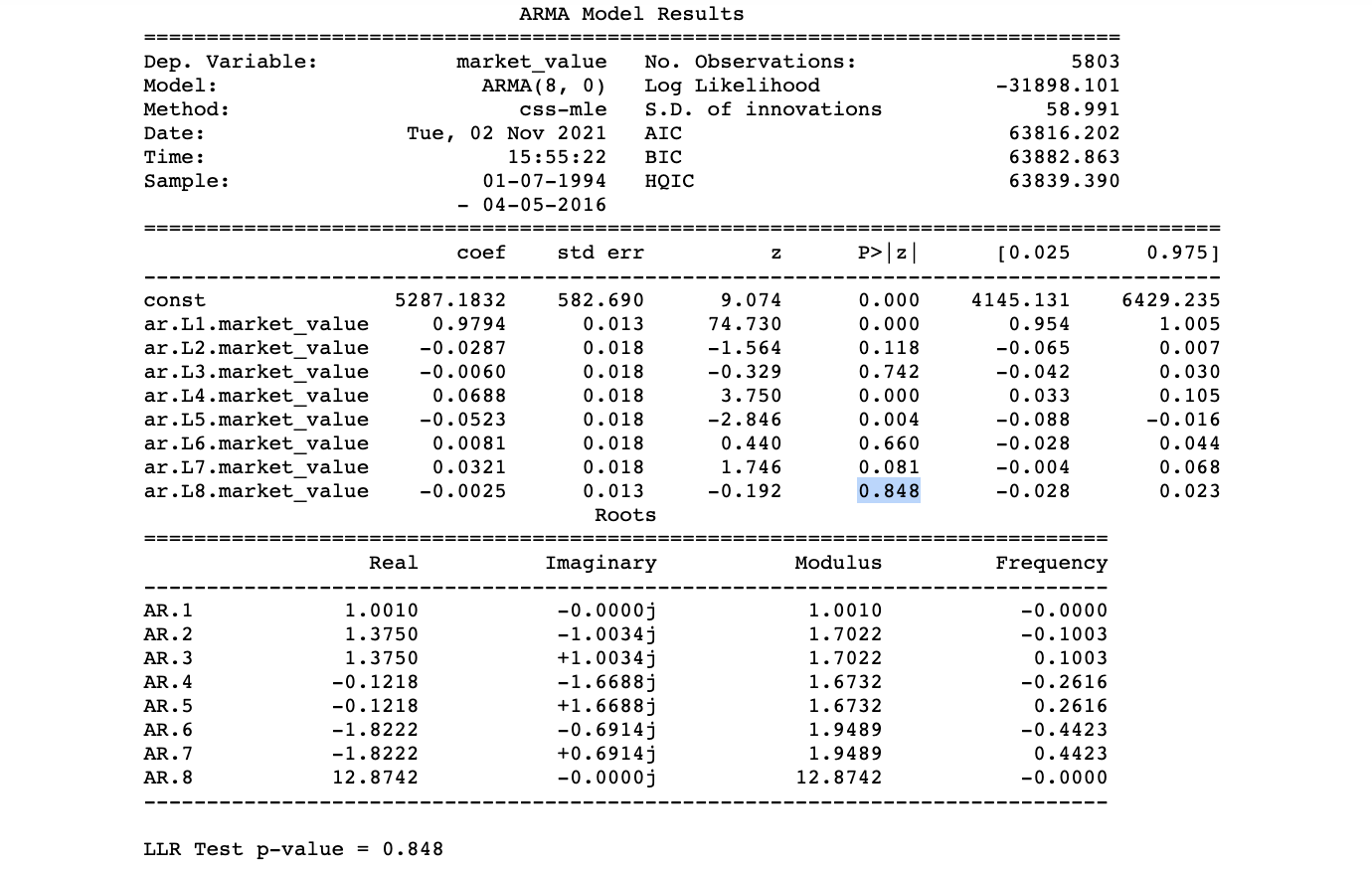
Explanation:
- AR(8) fails the LLR Test => does NOT provide significantly higher Log-Likelihood
- AR(8) has higher Information Criteria
- Including prices from eight periods ago does NOT improve the AR model
- We stop with the AR(7), even though it may contain some non-significant values
Using Returns instead of Prices
Since the market_value extracted from a non-stationary process (by DF-Test)
- we shouldn’t rely on AR Models to make accurate forecasts
- Solution: transform the data set, so that it fits the
stationaryassumptions- the common approach is to use
returnsinstead ofpriceswhen measuring financial indices returns: the % change (percentage values) between the values for two consecutive periods
- the common approach is to use
|
|
ACF and PACF of Returns
|
|
Output:
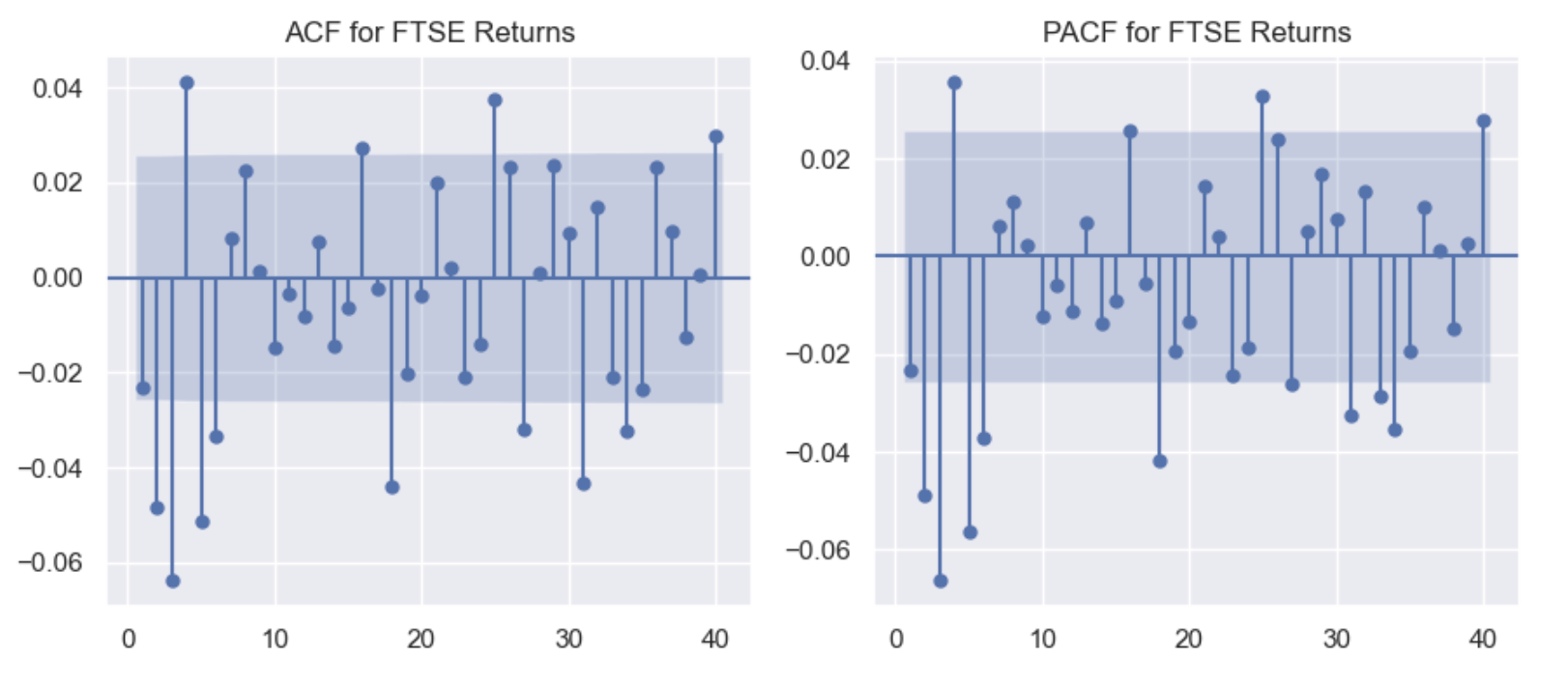
Explanation:
- ACF: Not ALL coefficients are positive or significant (as ACF for
Prices)- values greatly vary in magnitude instead of being close to 1
- Consecutive values move in different directions
- this suggests that
returnsover the entire week are relevant to those of the current one - negative relationship may have some form of natural adjustment occuring in the market
- to avoid falling in a big trend (avoid clustering)
- this suggests that
- PACF: Prices today often move in the opposite direction of prices yesterday
- Price increases following price decreases
- The majority of effects they have on current values should already be accounted for
Fitting an AR(1) Model for Returns
|
|
Fitting an Higher-Lag AR Model For Returns
|
|
Normalizing Values
Map every value of the sample space to the percentage of the benchmark (first value of the set)
- the resulting series is much easier to compare with other Time Series
- this gives us a better understanding of which ones to invest and which ones to avoid
|
|
Suppose historically, the S&P provides significantly higher returns (3%) than NIKKEI (which yields a steady 2% increase over a given period)
- then if both returns are around 3% for the period we are observing,
NIKKEIis significantly outperforming its expectations
To avoid any biased comparision when analyzing the two sets, we often rely on normalized returns
- which account for the absolute profitability of the investment in contrast to prices
- they allows to compare the relative profitability as opposed to non-normalized returns
|
|
- Normalizing does NOT affect stationarity and model selection
Analysing the Residuals
Ideally, the residuals should follow a Random Walk Process, so they should be stationary
Residuals of Prices
|
|
Residuals for Return
|
|
ACF of Residuals
Recall: the coefficients for the ACF of White Noise should ALL be 0
- Examine the ACF of the Residuals from a fitted model to make sure the errors of predictions are Random
- if the residuals are non-random, then there is a pattern that needs to be accounted for
|
|
Output:
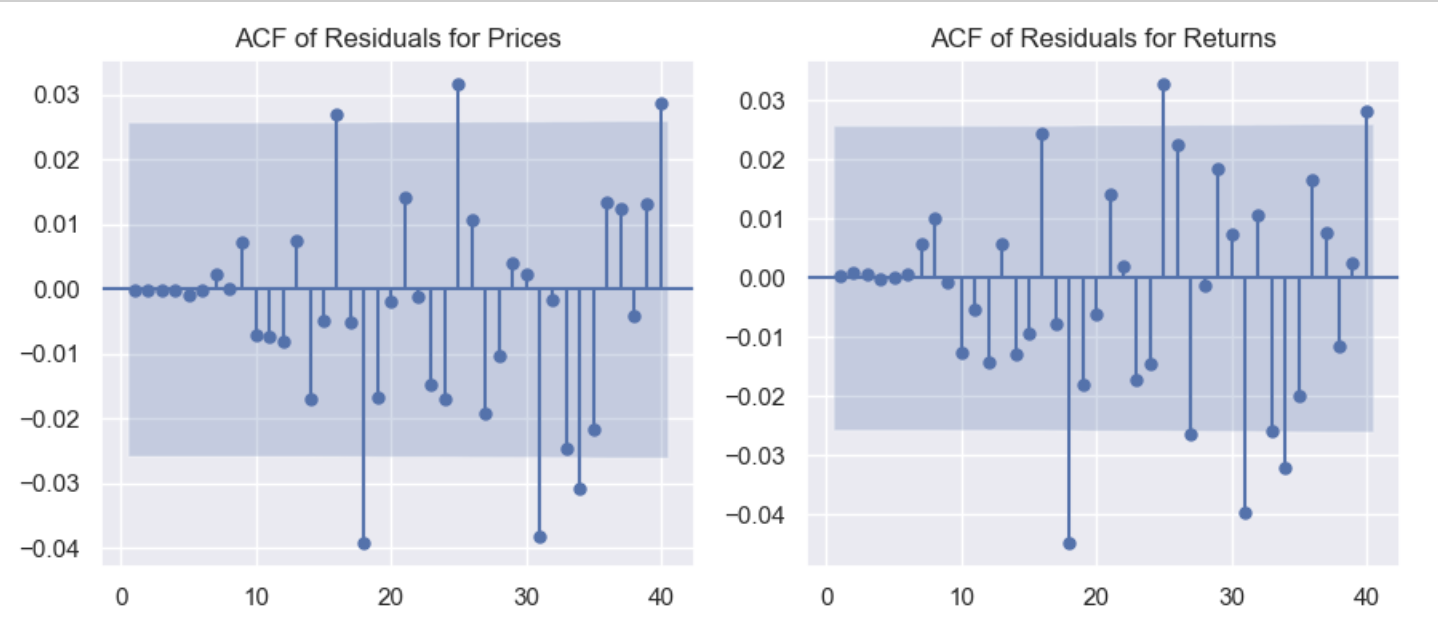
Explanation:
- The majority of coefficients fall within the blue region
- NOT significantly different from 0, which fits the characteristics of white noise
- The few points outside the blue area lead us to
believe there's a better predictor
Unexpected Shocks from Past Periods
AutoRegressive Models need time to adjust from a Big, Unexpected Shock
- because AR models rely on past data, regardless of how close predictions are
There are Self-Correcting Models that take into account past residuals, adjust to unexpected shocks more quickly
- because the predictions are corrected immediately following a big error
- the more errors examined, the more adapted model is to handle unforeseen errors
Moving Average(MA) Models perform well at predicting Random Walk datasets
- because they always adjust from the error of the previous period
- because absorbing shocks allows the mean to move accordingly
This gives the model prediction a much greater chance to move in a similar direction to the values it is trying to predict
- it also stops the model from greatly diverging, which is useful for non-stationary data
10. The Moving Average (MA) Model
$$r_t = c + \theta_1\epsilon_{t-1}+\epsilon_t$$
- $|\theta_n| < 1$ to prevent compounded effects exploding in magnitude
- $\epsilon_t$ and $\epsilon_{t-1}$: Residuals for the current and past period
A Simple MA Model is equivalent to an infinite AR model with certain restrictions
- difference: MA models determine the maximum amount of lags based on ACF (AR models rely on PACF)
- becaused the MA models aren’t based on past period returns
- determine which lagged values have a significant direct effect on the present-day ones is NOT relevant
1. Fitting a MA(1) Model for Returns
|
|
Output:
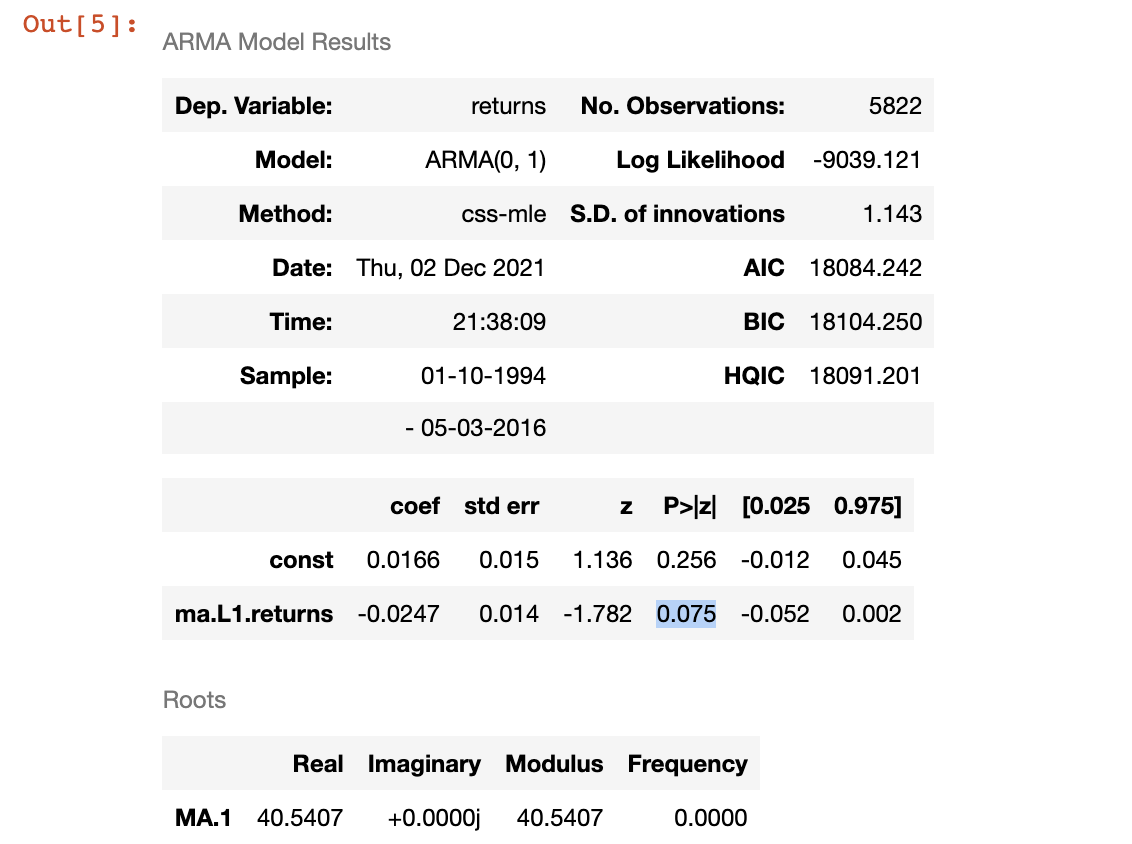
Explanation:
The coefficient for the one-lag-ago residual is significant at 0.10 significant level but not significant 0.05 level
- since the first coefficient of the ACF for Returns is NOT significantly different from 0 (within the blue area)
2. Fitting Higher-Lag MA Models
|
|
ACF for Returns can give us some hints:
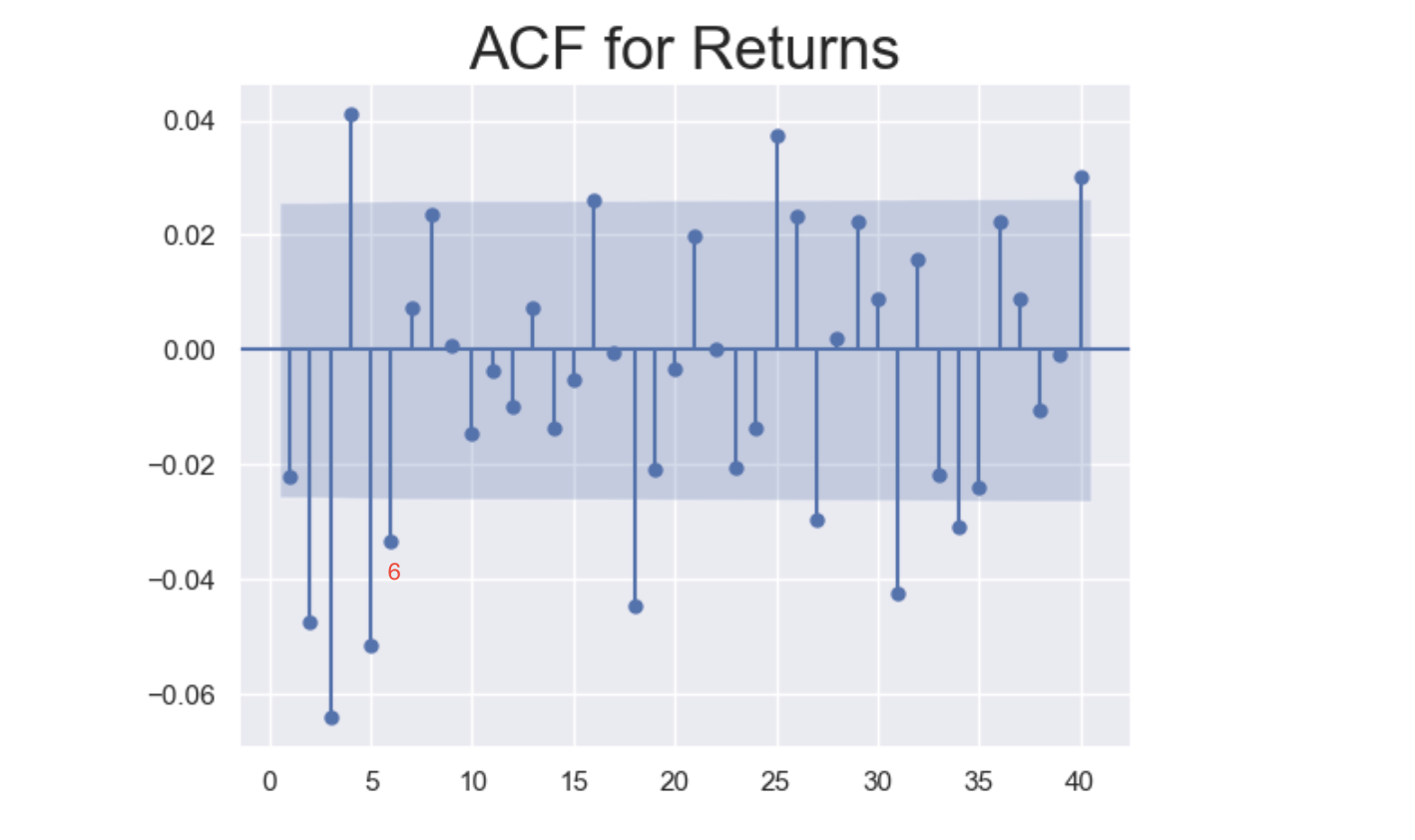
3. Examining the MA Model’s Residuals
We estimate the Standard Deviation of the residual, we can know how far off we can hypothetically be with our predictions
- using the 3 standard deviations rule, we can get a good idea of what interval 99.7% of the data will fall into
|
|
Output:
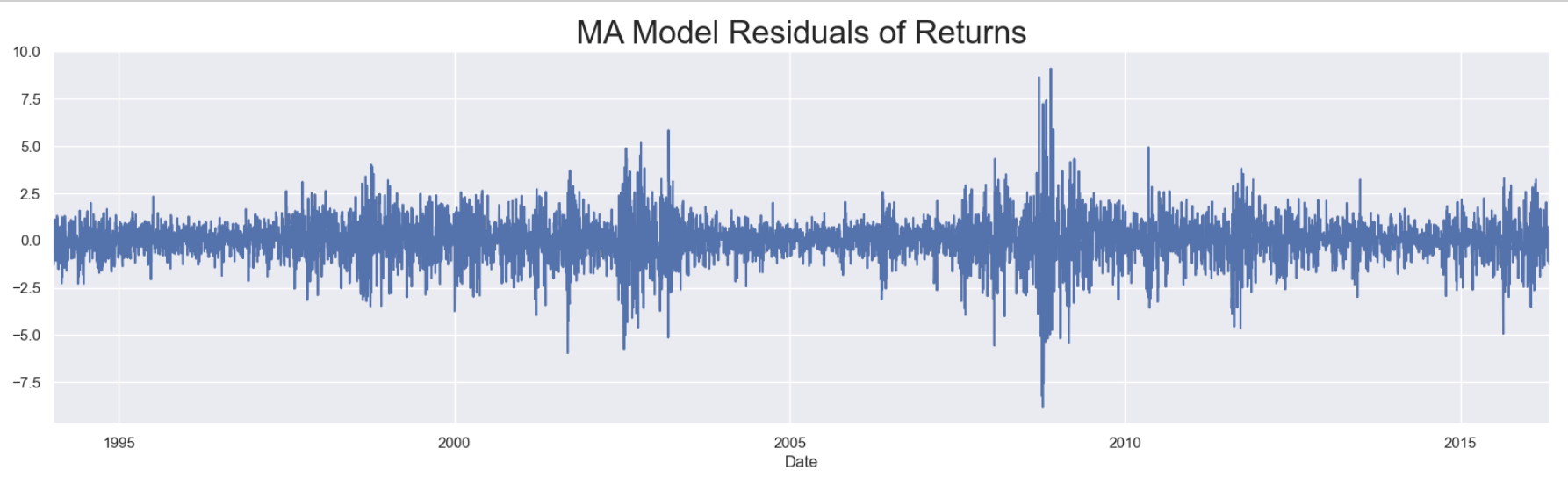
Exclude the .com and house price bubbles, the residuals are random
- to test if the residuals resemble a white noise process, we can check for stationary
- if the data is non-stationary, it can’t be considered white noise
|
|
Check ACF
- since a white noise process produces completely random data
- so that ACF coefficients should NOT be significantly different from zero
|
|
Output:
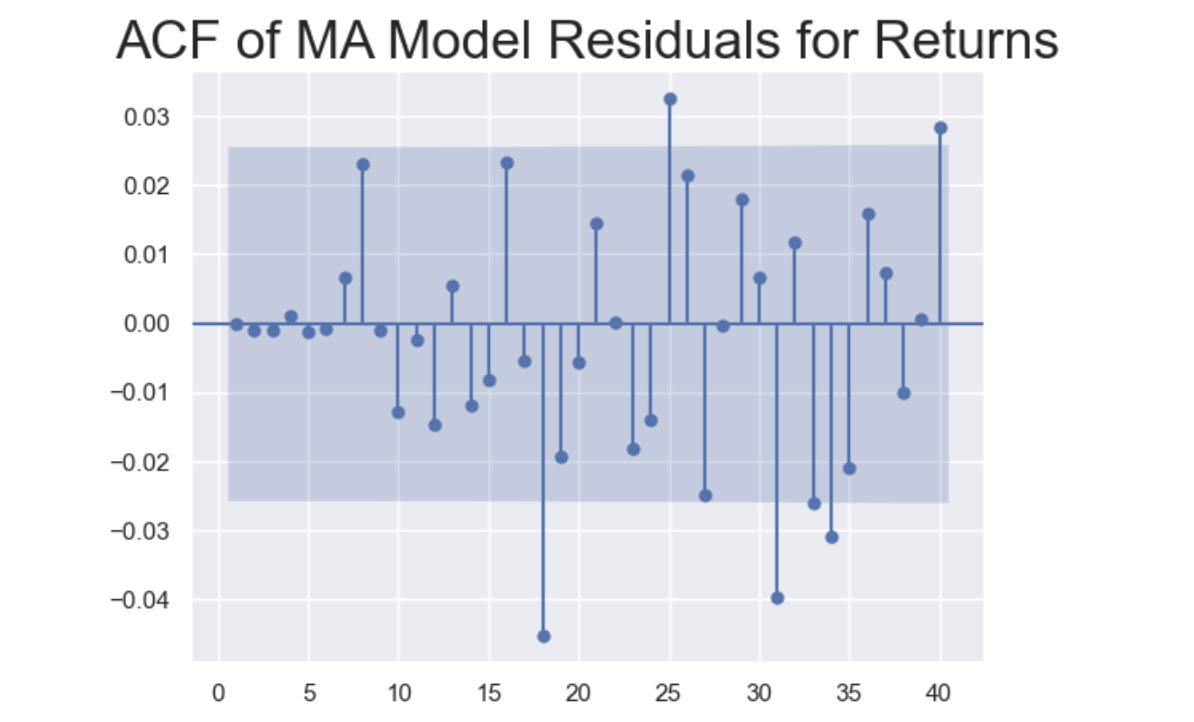
Explanation:
None of the first 17 lags are significant
- the first 6 coefficients are incorporated into the MA Model, so they are close to 0.
- the following 11 insignificant lags show that how well MA(6) model perform
Markets adjust to shocks, so values and errors far in the past lose relevance
- the ACF suggests that the residual data resembles white noise, which means the errors don’t follow a pattern
4. MA Model Selection for Normalized Returns
To compare different market indexes, using the normalized values is important
5. MA Model for Non-Stationary Prices
AR models are less reliable when estimating non-stationary prices