Deep Learning Notes 02 | Deep Neural Network
Contents
4. Deep Neural Networks
Why Deep ?
Logistic Regression and Single Layer Neural Networks perform well on some Simple Binary Classification Problems
- Deep Neural Networks (or Deep Learning) can solve more complex problems
- Neuroscientists believe that the human brain also starts off detecting simple things like edges to complex things like faces
- Layers “learn” simpler functions to more complex functions
Face Detection:
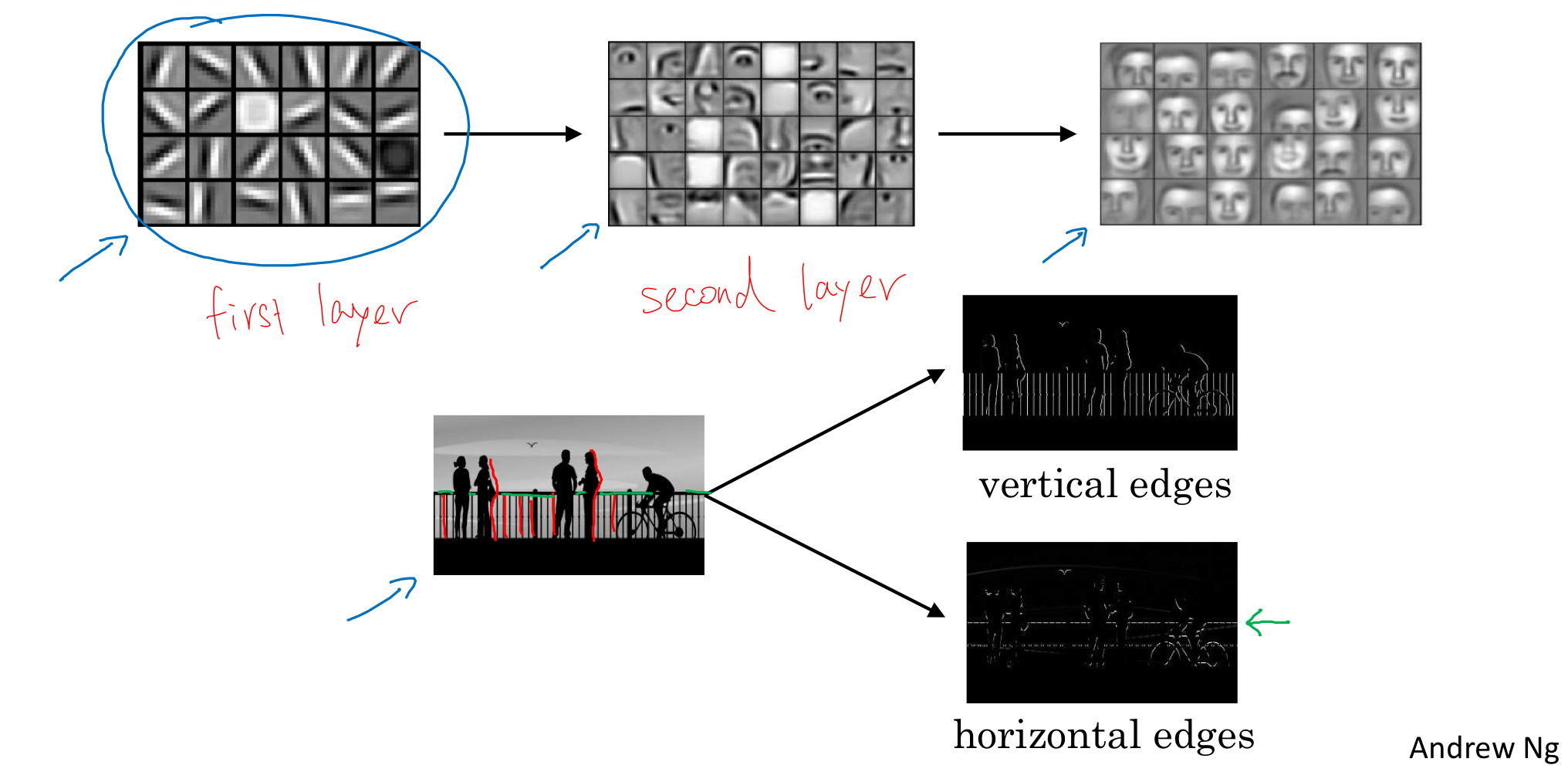
- The first layer of the neural network could be considered as Edge Detector
- each hidden unit may figure out different edge orintation (horizontal or vertical edges)
- The second layer could group the edges detected in first layer together
- different units may detect different parts of faces (eyes, noses,..)
- The third layer could recognize or detect different types of faces
Speech Recognition:
- The first layer of the neural network might learn to detect low-level audio waveform features
- up/down tone, white noise,
- The second layer learns to detect different basic units of sound (or phoneme)
- The third layer may learn to detect words and then sentences…
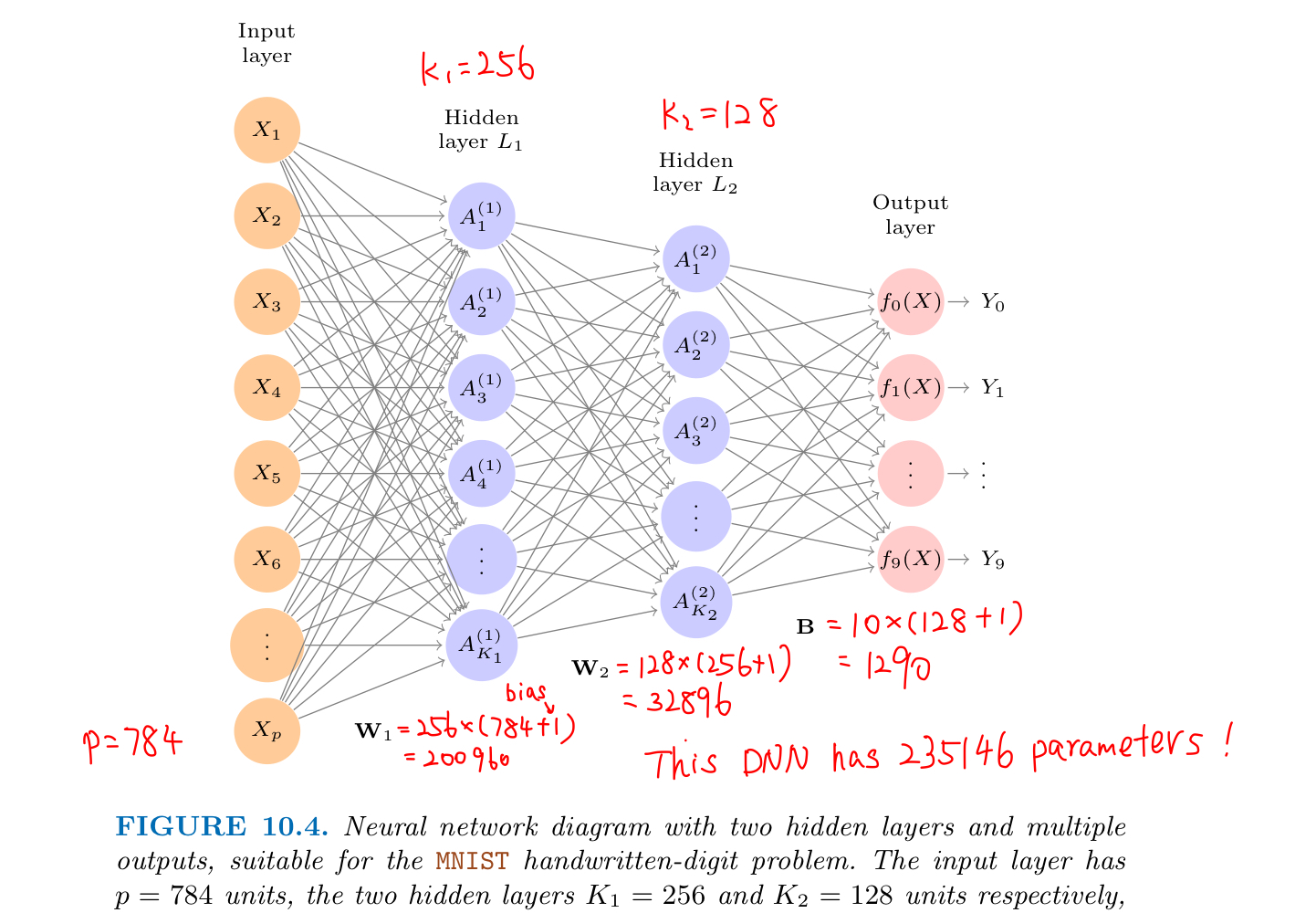
Hand-Written Digit Recognition
The idea is to build a Deep Neural Network to classify the images into their correct digit class 0-9:
- each imput vector $X$ stores one image that has p = 28 x 28 = 784 pixels, each of which is an eight-bit grayscale value between 0 and 255
- the output is the class label, represented by a vector $Y = (Y_0, Y_1, …, Y_9)$ of 10 dummy variables
- e.g. Y = (0,0,0,0,0,1,0,0,0,0) represents 5
- this is called one-hot encoding in Machine Learning community
- it has two hidden layers $L_1$ (256 units) and $L_2$ (128 units)
Build L-Layer DNN
Step 1: Random Initialization
- use
np.random.randn(layer_dims[l], layer_dims[l-1]) * 0.01
|
|
Step 2: Forward Propagation
- records all intermediate values in “caches”
|
|
Step 3: Compute the cross-entropy Cost
|
|
Step 5: Backward Propagation
|
|
Step 6: Update Parameters
|
|
Step 7: Integrate DNN Model
|
|