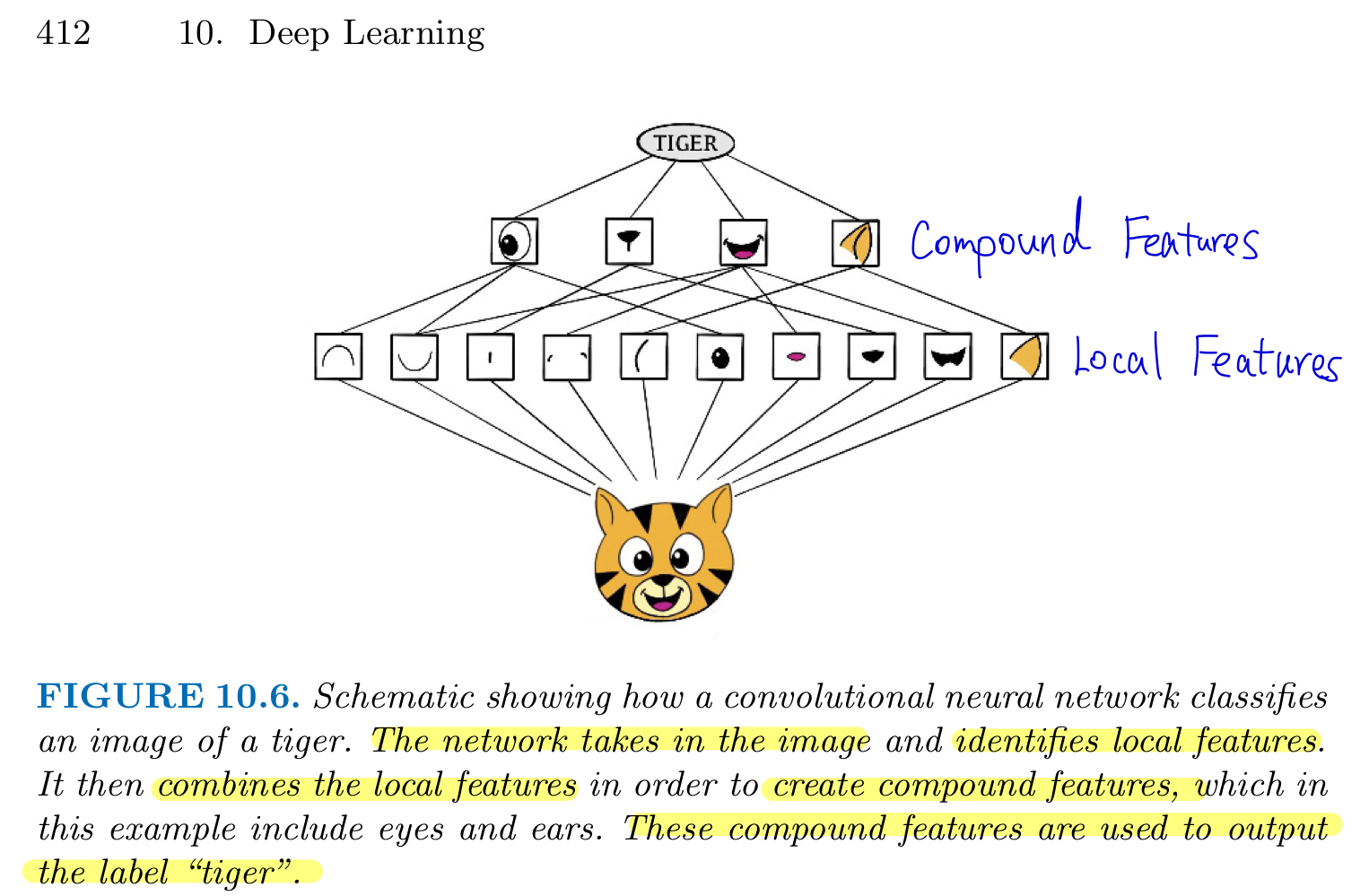
CNNs mimic to some degree how humans classify images, by recognizing specific features or patterns anywhere in the image that distinguish each particular object class.
the network first identifies low-level features in the input image
such as small edges, patches of color..
these low-level features are then combined to form higher-level features
such as ears, eyes..
finally, the presence or absence of these higher-level features contributes to the probability of any given output class
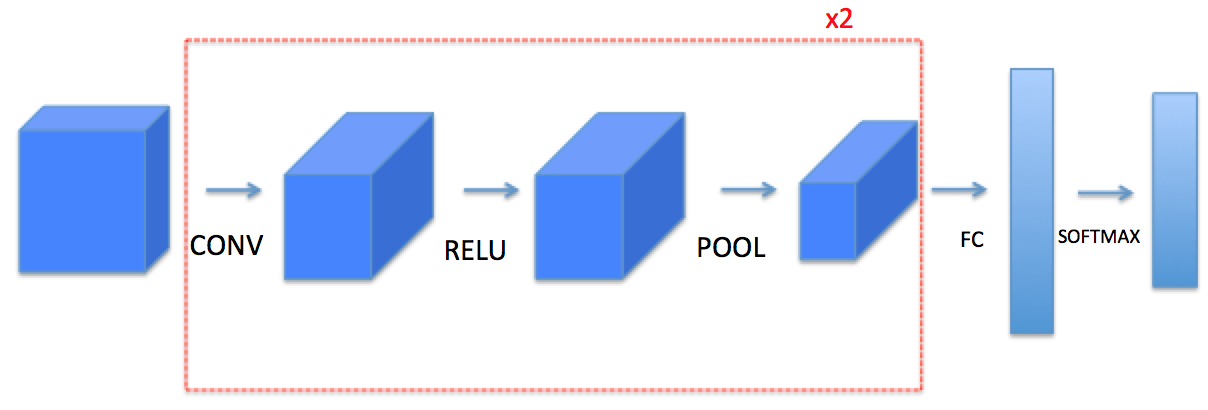
A CNN build up this hierarchy by combining two specialized types of hidden layers
Convolution Layers: made up of a large number of Convolution Filters, search for instances of small patterns in the image (after padding)
Pooling Layers:Downsample these patterns to select a prominent subset
0. Import Packages
1
2
3
4
5
6
7
8
9
10
11
12
13
14
importnumpyasnpimporth5pyimportmatplotlib.pyplotaspltfrompublic_testsimport*%matplotlibinlineplt.rcParams['figure.figsize']=(5.0,4.0)# set default size of plotsplt.rcParams['image.interpolation']='nearest'plt.rcParams['image.cmap']='gray'%load_extautoreload%autoreload2np.random.seed(1)
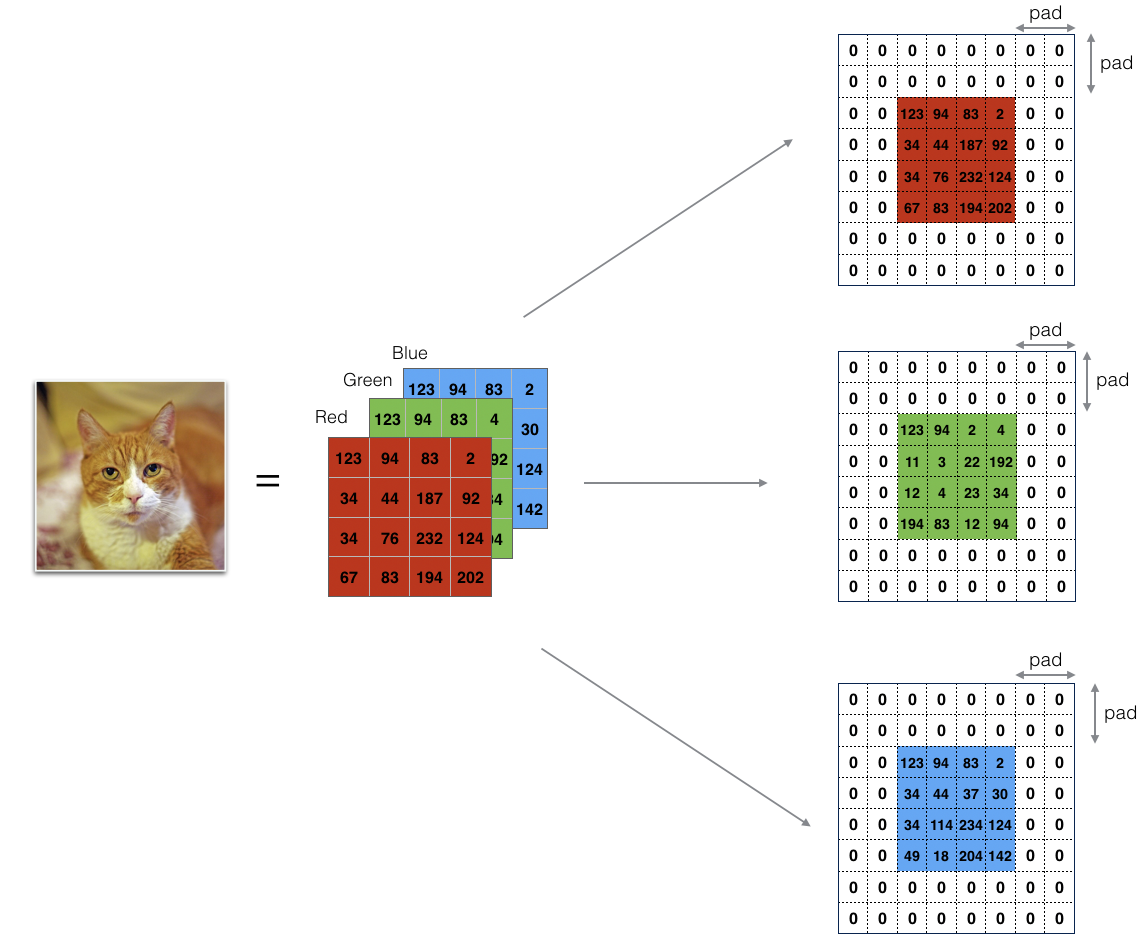
1. Zero-Padding
Zero-padding adds zeros around the border of an image:
The main benefits of padding are:
allows to use a CONV layer without necessarily shrinking the height and width of the volumes.
This is important for building deeper networks, since otherwise the height/width would shrink as you go to deeper layers.
An important special case is the “same” convolution, in which the height/width is exactly preserved after one layer.
helps to keep more of the information at the border of an image.
Without padding, very few values at the next layer would be affected by pixels at the edges of an image.
defzero_pad(X,pad):"""
Pad with zeros all images of the dataset X. The padding is applied to the height and width of an image,
as illustrated in Figure 1.
Argument:
X -- python numpy array of shape (m, n_H, n_W, n_C) representing a batch of m images
pad -- integer, amount of padding around each image on vertical and horizontal dimensions
Returns:
X_pad -- padded image of shape (m, n_H + 2 * pad, n_W + 2 * pad, n_C)
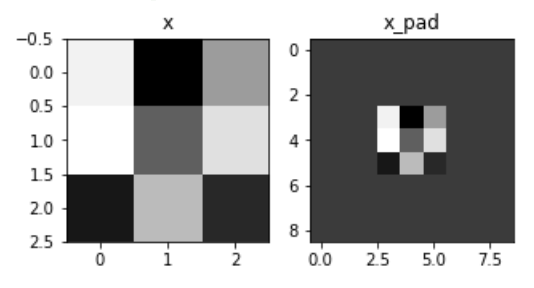
"""X_pad=np.pad(X,((0,0),(pad,pad),(pad,pad),(0,0)),mode='constant',constant_values=(0,0))returnX_padnp.random.seed(1)x=np.random.randn(4,3,3,2)# x.shapex_pad=zero_pad(x,3)# x_pad.shape = (4, 9, 9, 2)fig,axarr=plt.subplots(1,2)axarr[0].set_title('x')axarr[0].imshow(x[0,:,:,0])axarr[1].set_title('x_pad')axarr[1].imshow(x_pad[0,:,:,0])
Output:
2. Single Step Filter of Convolution
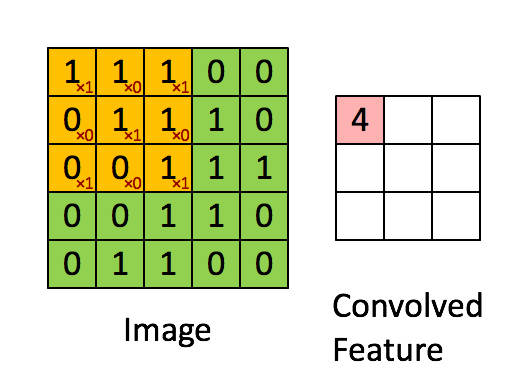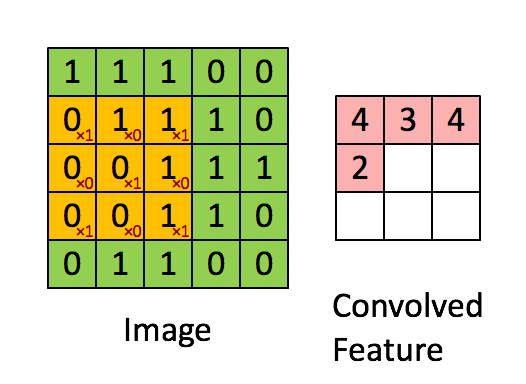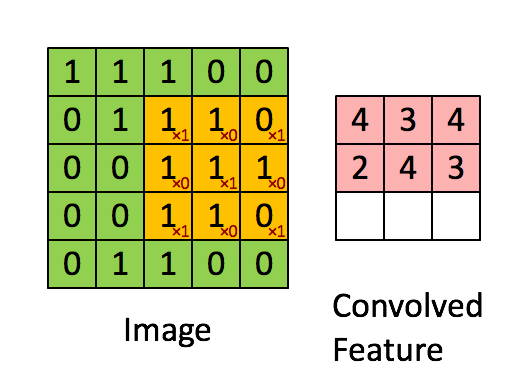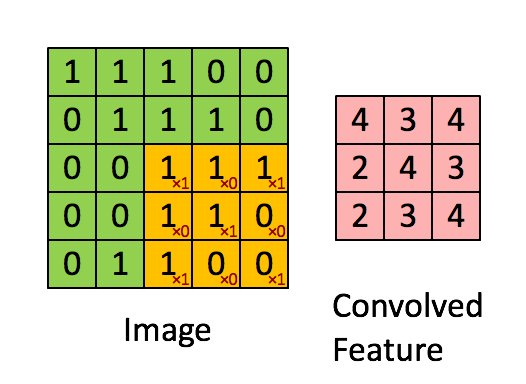
A Convolution extracts features from an input image by taking the dot product between the input data and a 3D array of weights (the filter)
the 2D output of the convolution is called the feature map
A Convolution layer is where the Filter slides over the image and computes the dot product
this transforms the input volume into an output volume of different size
Above is the Convolution Operation with a filter of 3 x 3 and a stride of 1
stride = amount the filter moves the window after each slide
defconv_single_step(a_slice_prev,W,b):"""
Apply one filter defined by parameters W on a single slice (a_slice_prev) of the output activation
of the previous layer.
Arguments:
a_slice_prev -- slice of input data of shape (f, f, n_C_prev)
W -- Weight parameters contained in a window - matrix of shape (f, f, n_C_prev)
b -- Bias parameters contained in a window - matrix of shape (1, 1, 1)
Returns:
Z -- a scalar value, the result of convolving the sliding window (W, b) on a slice x of the input data
"""# Element-wise product between a_slice_prev and W. Do not add the bias yet.s=np.multiply(a_slice_prev,W)# Sum over all entries of the volume s.Z=np.sum(s)# Add bias b to Z. Cast b to a float() so that Z results in a scalar value.Z=Z+float(b)returnZ
3. Forward Pass in CNN
3.1. Convolutional Layer Forward Pass
In the forward pass, we will take many filters and convolve them on the input,
each convolution gives a 2D matrix output
and then stack these outputs to get a 3D output volume
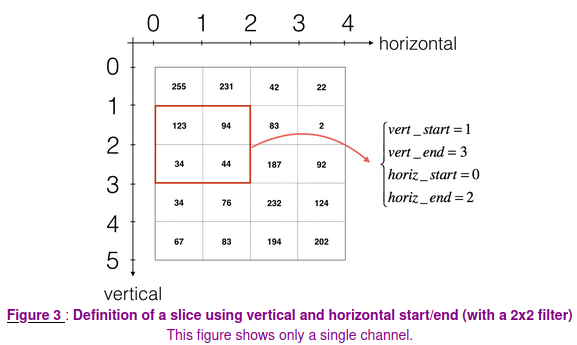
To define a slice, we need to first define its 4 corners:
vert_start, vert_end, horiz_start, horiz_end
Output shape of the convolution to the input shape are:
use int() to apply the ‘floor’ operation in python code
defconv_forward(A_prev,W,b,hparameters):"""
Implements the forward propagation for a convolution function
Arguments:
A_prev -- output activations of the previous layer,
numpy array of shape (m, n_H_prev, n_W_prev, n_C_prev)
W -- Weights, numpy array of shape (f, f, n_C_prev, n_C)
b -- Biases, numpy array of shape (1, 1, 1, n_C)
hparameters -- python dictionary containing "stride" and "pad"
Returns:
Z -- conv output, numpy array of shape (m, n_H, n_W, n_C)
cache -- cache of values needed for the conv_backward() function
"""# Retrieve dimensions from A_prev's shape (≈1 line)(m,n_H_prev,n_W_prev,n_C_prev)=A_prev.shape# Retrieve dimensions from W's shape(f,f,n_C_prev,n_C)=W.shape# Retrieve information from "hparameters"stride=hparameters["stride"]pad=hparameters["pad"]# Compute the dimensions of the CONV output volume using the formula given above.# Hint: use int() to apply the 'floor' operation.n_H=int((n_H_prev+2*pad-f)/stride)+1n_W=int((n_W_prev+2*pad-f)/stride)+1# Initialize the output volume Z with zeros. (≈1 line)Z=np.zeros((m,n_H,n_W,n_C))# Create A_prev_pad by padding A_prevA_prev_pad=zero_pad(A_prev,pad)foriinrange(m):# loop over the batch of training examplesa_prev_pad=A_prev_pad[i]# Select ith training example's padded activationforhinrange(n_H):# loop over vertical axis of the output volume# Find the vertical start and end of the current "slice"vert_start=stride*hvert_end=vert_start+fforwinrange(n_W):# loop over horizontal axis of the output volume# Find the horizontal start and end of the current "slice"horiz_start=stride*whoriz_end=horiz_start+fforcinrange(n_C):# loop over channels (= #filters) of the output volume# Use the corners to define the (3D) slice of a_prev_pada_slice_prev=a_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:]# Convolve the (3D) slice with the correct filter W and bias b, to get back one output neuron.weights=W[:,:,:,c]biases=b[:,:,:,c]Z[i,h,w,c]=conv_single_step(a_slice_prev,weights,biases)# Save information in "cache" for the backpropcache=(A_prev,W,b,hparameters)returnZ,cache
3.2. Pooling Layer Forward Pass
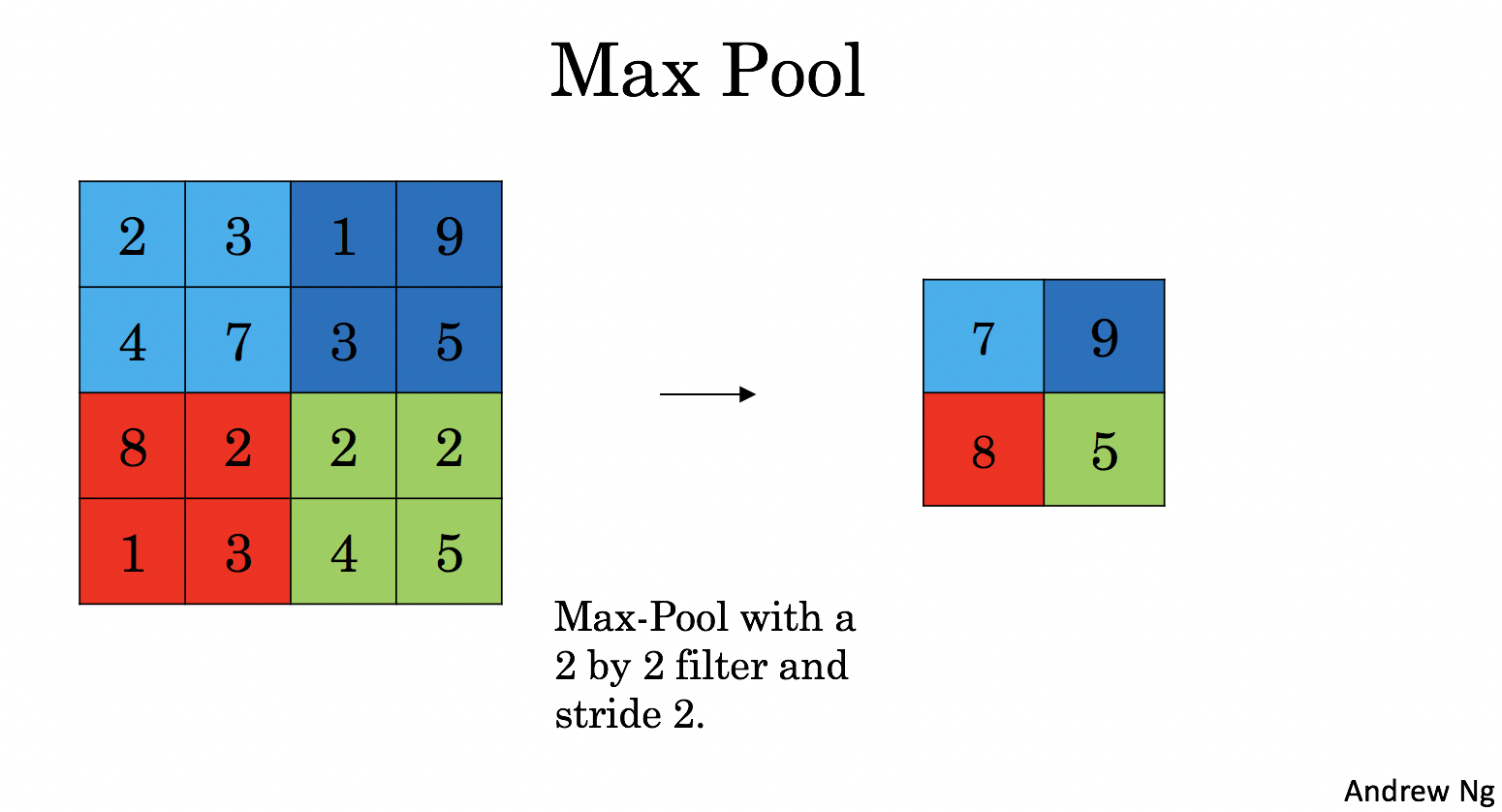
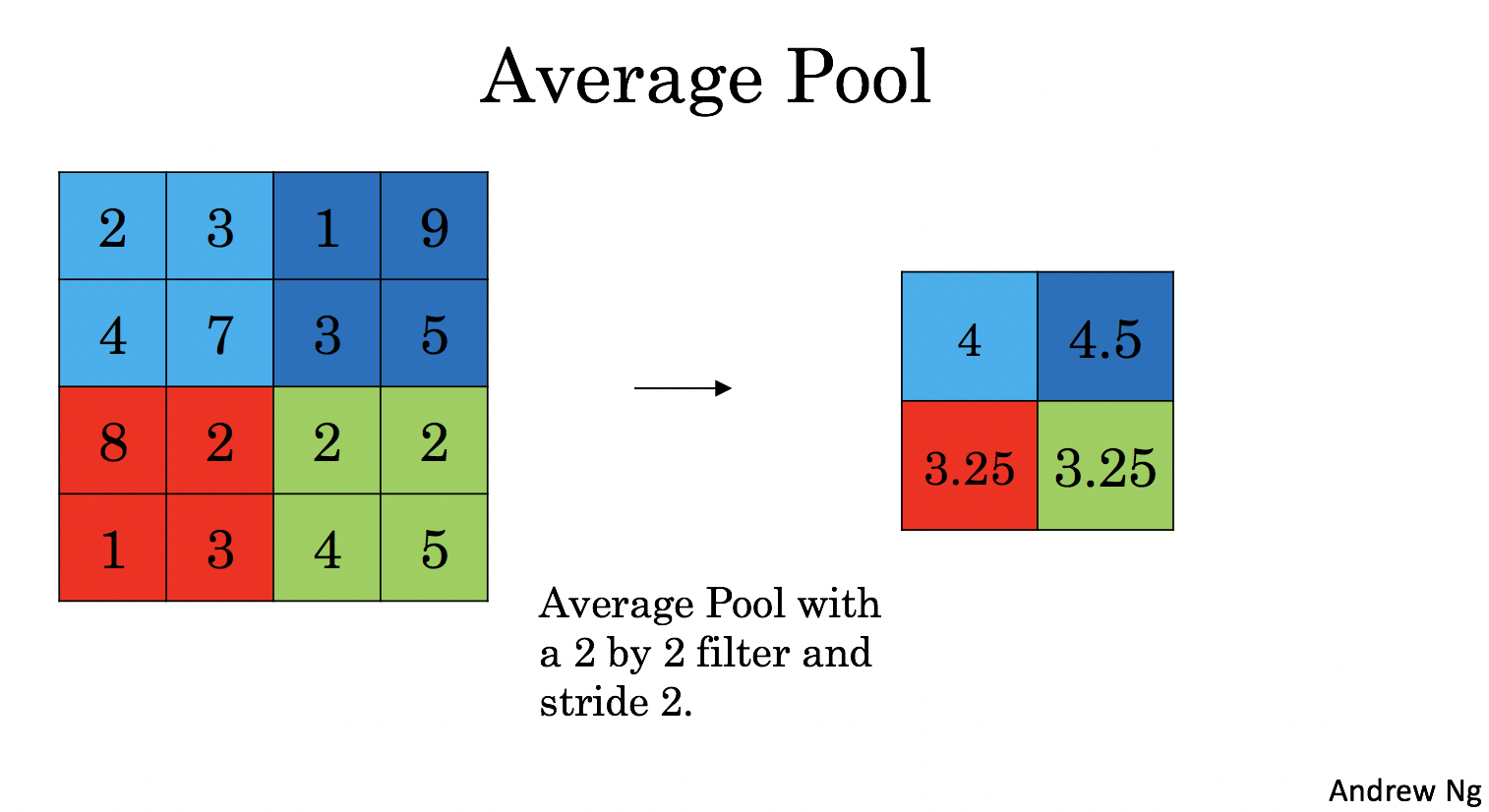
The Pooling layer (POOL) gradually reduces the height and width of the input by sliding a 2D window over each specified region.
it helps reduce computation, and
make feature detectors more invariant to its position in the input.
There are two types of pooling layers:
As there’s NO padding, the output shape of the POOL to the input shape is:
defpool_forward(A_prev,hparameters,mode="max"):"""
Implements the forward pass of the pooling layer
Arguments:
A_prev -- Input data, numpy array of shape (m, n_H_prev, n_W_prev, n_C_prev)
hparameters -- python dictionary containing "f" and "stride"
mode -- the pooling mode you would like to use, defined as a string ("max" or "average")
Returns:
A -- output of the pool layer, a numpy array of shape (m, n_H, n_W, n_C)
cache -- cache used in the backward pass of the pooling layer, contains the input and hparameters
"""# Retrieve dimensions from the input shape(m,n_H_prev,n_W_prev,n_C_prev)=A_prev.shape# Retrieve hyperparameters from "hparameters"f=hparameters["f"]stride=hparameters["stride"]# Define the dimensions of the outputn_H=int(1+(n_H_prev-f)/stride)n_W=int(1+(n_W_prev-f)/stride)n_C=n_C_prev# Initialize output matrix AA=np.zeros((m,n_H,n_W,n_C))foriinrange(m):# loop over the training examplesa_prev_slice=A_prev[i]forhinrange(n_H):# loop on the vertical axis of the output volume# Find the vertical start and end of the current "slice"vert_start=stride*hvert_end=vert_start+fforwinrange(n_W):# loop on the horizontal axis of the output volume# Find the vertical start and end of the current "slice"horiz_start=stride*whoriz_end=horiz_start+fforcinrange(n_C):# loop over the channels of the output volume# Use the corners to define the current slice on the ith training example of A_prev, channel c.a_slice_prev=a_prev_slice[vert_start:vert_end,horiz_start:horiz_end,c]# Compute the pooling operation on the slice.ifmode=="max":A[i,h,w,c]=np.max(a_slice_prev)elifmode=="average":A[i,h,w,c]=np.mean(a_slice_prev)# Store the input and hparameters in "cache" for pool_backward()cache=(A_prev,hparameters)# Making sure your output shape is correctassert(A.shape==(m,n_H,n_W,n_C))returnA,cache
4. Backpropagation in CNN
In Modern Deep Learning Frameworks (Tensorflow, Pytorch, …), we just need to implement the forward pass, and the framework takes care of the backward pass, so most deep learning engineers don’t need to bother with the details of the backward pass.
defconv_backward(dZ,cache):"""
Implement the backward propagation for a convolution function
Arguments:
dZ -- gradient of the cost with respect to the output of the conv layer (Z), numpy array of shape (m, n_H, n_W, n_C)
cache -- cache of values needed for the conv_backward(), output of conv_forward()
Returns:
dA_prev -- gradient of the cost with respect to the input of the conv layer (A_prev),
numpy array of shape (m, n_H_prev, n_W_prev, n_C_prev)
dW -- gradient of the cost with respect to the weights of the conv layer (W)
numpy array of shape (f, f, n_C_prev, n_C)
db -- gradient of the cost with respect to the biases of the conv layer (b)
numpy array of shape (1, 1, 1, n_C)
"""# Retrieve information from "cache"(A_prev,W,b,hparameters)=cache# Retrieve dimensions from A_prev's shape(m,n_H_prev,n_W_prev,n_C_prev)=A_prev.shape# Retrieve dimensions from W's shape(f,f,n_C_prev,n_C)=W.shape# Retrieve information from "hparameters"stride=hparameters["stride"]pad=hparameters["pad"]# Retrieve dimensions from dZ's shape(m,n_H,n_W,n_C)=dZ.shape# Initialize dA_prev, dW, db with the correct shapesdA_prev=np.zeros(A_prev.shape)dW=np.zeros(W.shape)db=np.zeros(b.shape)# b.shape = [1,1,1,n_C]# Pad A_prev and dA_prevA_prev_pad=zero_pad(A_prev,pad)dA_prev_pad=zero_pad(dA_prev,pad)foriinrange(m):# loop over the training examples# select ith training example from A_prev_pad and dA_prev_pada_prev_pad=A_prev_pad[i]da_prev_pad=dA_prev_pad[i]forhinrange(n_H):# loop over vertical axis of the output volumeforwinrange(n_W):# loop over horizontal axis of the output volumeforcinrange(n_C):# loop over the channels of the output volume# Find the corners of the current "slice"vert_start=stride*hvert_end=vert_start+fhoriz_start=stride*whoriz_end=horiz_start+f# Use the corners to define the slice from a_prev_pada_slice=a_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:]# Update gradients for the window and the filter's parameters using the code formulas given aboveda_prev_pad[vert_start:vert_end,horiz_start:horiz_end,:]+=W[:,:,:,c]*dZ[i,h,w,c]dW[:,:,:,c]+=a_slice*dZ[i,h,w,c]db[:,:,:,c]+=dZ[i,h,w,c]# Set the ith training example's dA_prev to the unpadded da_prev_pad (Hint: use X[pad:-pad, pad:-pad, :])dA_prev[i,:,:,:]=da_prev_pad[pad:-pad,pad:-pad,:]# Making sure your output shape is correctassert(dA_prev.shape==(m,n_H_prev,n_W_prev,n_C_prev))returndA_prev,dW,db
4.2. Pooling Layer Backward Pass
We need first implement a function that creates a “mask” to keep track of where the maximum of the matrix is.
mask[i,j] = 1 if X[i,j] == np.max(X)
mask[i,j] = 0 if X[i,j] != np.max(X)
1
2
3
4
5
6
7
8
9
10
11
12
13
defcreate_mask_from_window(x):"""
Creates a mask from an input matrix x, to identify the max entry of x.
Arguments:
x -- Array of shape (f, f)
Returns:
mask -- Array of the same shape as window, contains a True at the position corresponding to the max entry of x.
"""mask=(x==np.max(x))returnmask
And we need then implement another function to equally distributedZ through a matrix of dimension shape
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
defdistribute_value(dz,shape):"""
Distributes the input value in the matrix of dimension shape
Arguments:
dz -- input scalar
shape -- the shape (n_H, n_W) of the output matrix for which we want to distribute the value of dz
Returns:
a -- Array of size (n_H, n_W) for which we distributed the value of dz
"""# Retrieve dimensions from shape(n_H,n_W)=shape# Compute the value to distribute on the matrixaverage=np.prod(shape)# Create a matrix where every entry is the "average" valuea=(dz/average)*np.ones(shape)returna
Finally, we can put everything together to compute backward propagation on a pooling layer:
defpool_backward(dA,cache,mode="max"):"""
Implements the backward pass of the pooling layer
Arguments:
dA -- gradient of cost with respect to the output of the pooling layer, same shape as A
cache -- cache output from the forward pass of the pooling layer, contains the layer's input and hparameters
mode -- the pooling mode you would like to use, defined as a string ("max" or "average")
Returns:
dA_prev -- gradient of cost with respect to the input of the pooling layer, same shape as A_prev
"""# Retrieve information from cache(A_prev,hparameters)=cache# Retrieve hyperparameters from "hparameters"stride=hparameters["stride"]f=hparameters["f"]# Retrieve dimensions from A_prev's shape and dA's shapem,n_H_prev,n_W_prev,n_C_prev=A_prev.shapem,n_H,n_W,n_C=dA.shape# Initialize dA_prev with zerosdA_prev=np.zeros(A_prev.shape)foriinrange(m):# loop over the training examples# select training example from A_preva_prev=A_prev[i,:,:,:]forhinrange(n_H):# loop on the vertical axisforwinrange(n_W):# loop on the horizontal axisforcinrange(n_C):# loop over the channels (depth)# Find the corners of the current "slice"vert_start=h*stridevert_end=h*stride+fhoriz_start=w*stridehoriz_end=w*stride+f# Compute the backward propagation in both modes.ifmode=="max":# Use the corners and "c" to define the current slice from a_preva_prev_slice=a_prev[vert_start:vert_end,horiz_start:horiz_end,c]# Create the mask from a_prev_slicemask=create_mask_from_window(a_prev_slice)# Set dA_prev to be dA_prev + (the mask multiplied by the correct entry of dA)dA_prev[i,vert_start:vert_end,horiz_start:horiz_end,c]+=mask*dA[i,h,w,c]elifmode=="average":# Get the value da from dAda=dA[i,h,w,c]# Define the shape of the filter as f x fshape=(f,f)# Distribute it to get the correct slice of dA_prev. i.e. Add the distributed value of da.dA_prev[i,vert_start:vert_end,horiz_start:horiz_end,c]+=distribute_value(da,shape)# Making sure your output shape is correctassert(dA_prev.shape==A_prev.shape)returndA_prev